In this article:
- Understanding Tensor Cores
- What are CUDA cores?
- What are Tensor Cores?
- How do Tensor Cores work?
- First Generation NVIDIA GPU Microarchitecture
- Second Generation NVIDIA GPU Microarchitecture
- Third Generation NVIDIA GPU Microarchitecture
- Fourth Generation NVIDIA GPU Microarchitecture
- Conclusion

Understanding Tensor Cores
Nvidia’s Tensor Core is a crucial technology in the latest GPU microarchitecture releases. With each generation, these specialized processing subunits have advanced since their introduction in Volta, providing a significant boost to GPU performance through automatic mixed precision training.
This article provides a summary of the Tensor Core capabilities in the Volta, Turing, and Ampere series of NVIDIA GPUs. By the end of this article, readers will have a clear understanding of the different types of NVIDIA GPU cores, how Tensor Cores facilitate mixed precision training for deep learning, how to distinguish the performance of each microarchitecture’s Tensor Cores, and how to recognize Tensor Core-powered GPUs.
What are CUDA cores?
To delve into the architecture and usefulness of Tensor Cores, it’s crucial to understand CUDA cores. NVIDIA’s proprietary parallel processing platform and API for GPUs, CUDA (Compute Unified Device Architecture), uses CUDA cores as the standard floating point unit in NVIDIA graphics cards. These cores have been a defining feature of NVIDIA GPU microarchitectures over the past decade, present in every NVIDIA GPU released during that time.
Each CUDA core performs calculations and executes one operation per clock cycle. While not as powerful as a CPU core, utilizing multiple CUDA cores in parallel for deep learning can greatly accelerate computations. In this article, we will explore the relationship between CUDA and Tensor Cores, how they work together to enable high-performance computing and the unique features of each NVIDIA GPU microarchitecture.
Before the introduction of Tensor Cores, CUDA cores were the primary hardware used for accelerating deep learning. However, GPUs that rely solely on CUDA cores are restricted by the number of available cores and the clock speed of each core, as they can only handle one computation per clock cycle. To overcome this bottleneck, NVIDIA developed the Tensor Core.
The Tensor Core revolutionized GPU performance by enhancing the ability to perform mixed-precision calculations, increasing the amount of data that can be processed simultaneously. In this blog post, we will explore the advantages of Tensor Cores over CUDA cores and how they contribute to high-performance computing in NVIDIA’s latest GPU microarchitectures.
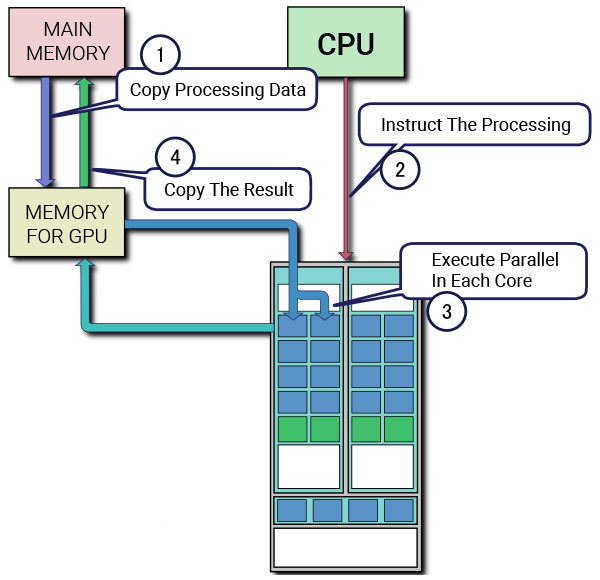
What are Tensor Cores?
Tensor Cores are unique cores designed to enable mixed precision training in deep learning. The first generation of Tensor Cores utilizes a fused multiply add computation, allowing for the multiplication and addition of two 4×4 FP16 matrices to a 4×4 FP16 or FP32 matrix.
Mixed precision computation is named as such because the input matrices can be low-precision FP16, while the output matrix is a higher precision FP32, resulting in faster computations with minimal loss of precision. This feature greatly enhances the performance of deep learning models.
As technology progressed, newer microarchitectures have expanded the capabilities of Tensor Cores to support even less precise computer number formats, further accelerating computations while maintaining the efficacy of the model. We will now delve deeper into the technicalities of Tensor Cores and their contributions to high-performance computing in deep learning.
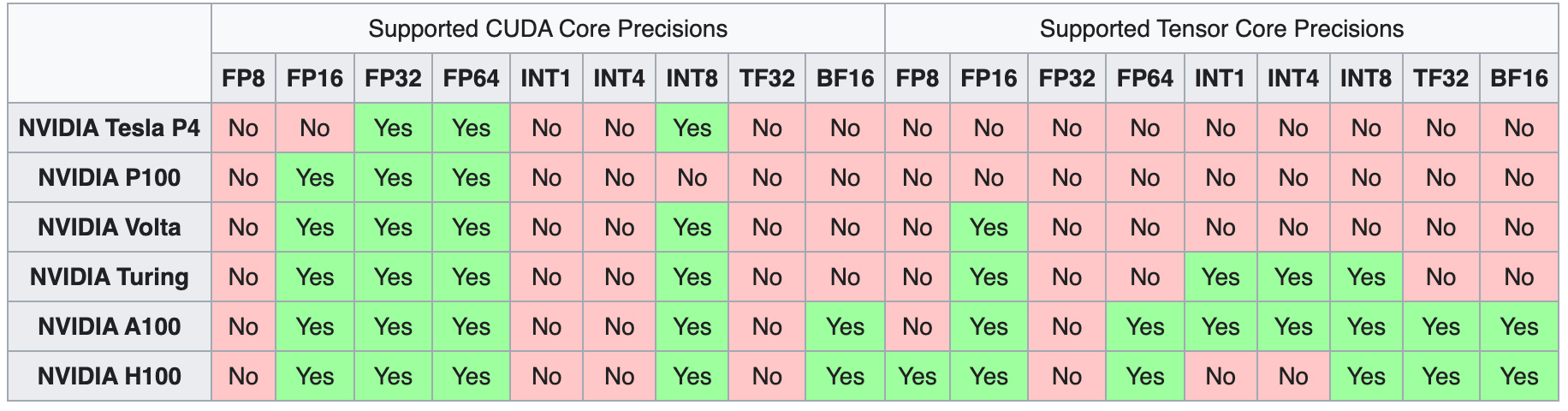
The introduction of the first generation of Tensor Cores began with the Volta microarchitecture, starting with the V100. As subsequent generations emerged, they were equipped with additional computer number precision formats, expanding the range of computations that can be performed.
In the following section, we will explore the unique features and improvements of each microarchitecture in regards to Tensor Cores and their impact on high-performance computing in deep learning.
How do Tensor Cores work?
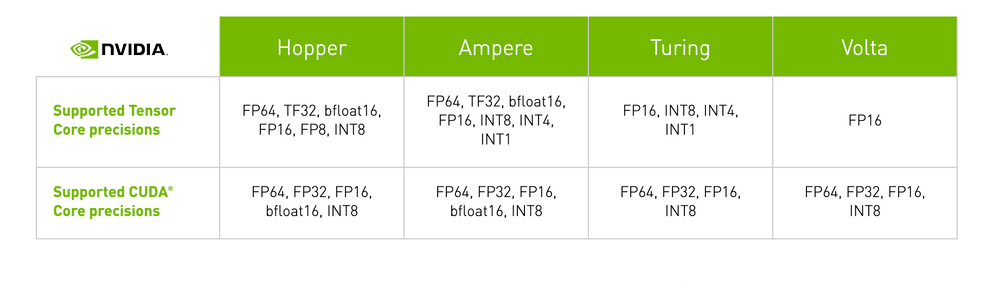
With each new generation of GPU microarchitecture, novel methodologies have been introduced to enhance the performance of Tensor Core operations. These advancements have expanded the range of computer number formats that Tensor Cores can operate on, resulting in a significant increase in GPU throughput with each iteration.
First Generation NVIDIA GPU Microarchitecture
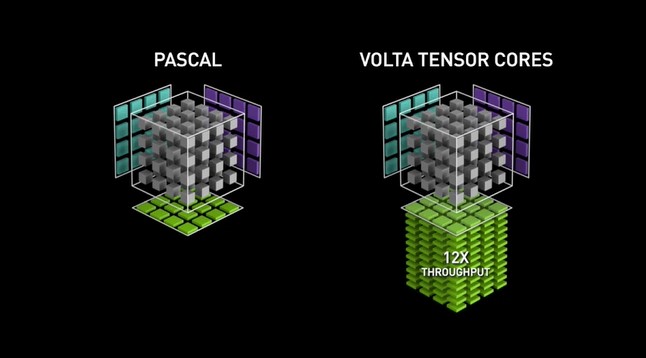
The Volta GPU microarchitecture marked the debut of the first generation of Tensor Cores, which facilitated mixed precision training using the FP16 number format. This development resulted in a massive potential throughput boost of up to 12x in teraFLOPs. The flagship V100 with its 640 cores provided up to 5x faster performance speed compared to the previous Pascal GPU generation.
Second Generation NVIDIA GPU Microarchitecture
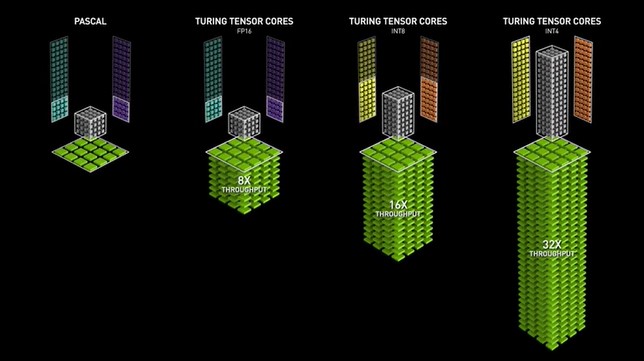
The Turing GPUs introduced the second generation of Tensor Cores, supporting precisions such as Int8, Int4, and Int1 in addition to FP16. These Tensor Cores enable mixed precision training operations, accelerating GPU performance by up to 32x compared to Pascal GPUs. Turing GPUs also feature Ray Tracing cores, which enhance graphic visualization properties like light and sound in 3D environments.
Third Generation NVIDIA GPU Microarchitecture
The Ampere line of GPUs boasts the third generation of Tensor Cores. By extending computational capability to FP64, TF32 and bfloat16 precisions, Ampere GPUs accelerate deep learning training and inference tasks even further. With features like specialization with sparse matrix mathematics, third-generation NVLink, and third-generation Ray Tracing cores, Ampere GPUs — specifically the data center A100.
Budget-conscious users can also take advantage of the powerful Ampere microarchitecture and third-generation Tensor Cores through the workstation GPU line, such as the A4000, A5000, and A6000. Implementing automatic mixed precision can accelerate training by an additional 2x with only a few lines of code.
The Ampere microarchitecture boasts advanced features like sparse matrix mathematics specialization, third-generation NVLink for lightning-fast multi-GPU interactions and third-generation Ray Tracing cores.
However, for those on a budget, the workstation GPU line, such as the A4000, A5000, and A6000, offer a more affordable way to access the powerful Ampere microarchitecture and its third-generation Tensor Cores.
Fourth Generation NVIDIA GPU Microarchitecture
In September 2022, NVIDIA released the Hopper microarchitecture, featuring the fourth generation of Tensor Cores. These Cores offer increased capability by adding support for FP8 precision formats, which NVIDIA claims can accelerate large language models by up to 30 times over the previous generation. The H100 is the first GPU to feature these new Tensor Cores, making it a powerful option for those seeking the latest in deep learning technology.
Conclusion
GPU technology advancements are closely linked with the evolution of Tensor Core technology. These cores enable high-performance mixed precision training and have enabled Volta, Turing, and Ampere GPUs to become the preferred machines for AI development. As outlined in this article, the progress from generation to generation of GPU is marked by improvements in Tensor Core capabilities.
Understanding the capabilities and differences between Tensor Cores is crucial to comprehending the significant performance boost each subsequent GPU generation brings to deep learning tasks. By leveraging these powerful cores, each generation, from Volta to Hopper, has paved the way for processing increasingly massive amounts of data at an unprecedented speed.










