In diesem artikel:
- Tensor Cores Verstehen
- Was sind CUDA Kerne?
- Was sind Tensor Cores?
- Wie funktionieren Tensor Cores?
- NVIDIA GPU-Mikroarchitektur der ersten Generation
- NVIDIA GPU-Mikroarchitektur der zweiten Generation
- NVIDIA GPU-Mikroarchitektur der dritten Generation
- NVIDIA GPU-Mikroarchitektur der vierten Generation
- Schlussfolgerung

Tensor Cores Verstehen
Der Tensor Core von Nvidia ist eine entscheidende Technologie in den neuesten Versionen der GPU-Mikroarchitektur. Mit jeder Generation haben sich diese spezialisierten Verarbeitungsuntereinheiten seit ihrer Einführung in Volta weiterentwickelt und sorgen durch automatisches Mixed-Precision-Training für eine deutliche Steigerung der GPU-Leistung.
Dieser Artikel bietet eine Zusammenfassung der Tensor Core-Funktionen in den NVIDIA-GPUs der Volta-, Turing- und Ampere-Serie. Am Ende dieses Artikels werden die Leser ein klares Verständnis der verschiedenen Arten von NVIDIA-GPU-Kernen haben, wie Tensor-Cores das Mixed-Precision-Training für Deep Learning erleichtern, wie man die Leistung der Tensor-Cores der einzelnen Mikroarchitekturen unterscheidet und wie man Tensor-Core-betriebene GPUs erkennt.
Was sind CUDA Kerne?
Um die Architektur und Nützlichkeit von Tensor Cores zu verstehen, ist es wichtig, die CUDA Cores zu kennen. NVIDIAs proprietäre parallele Verarbeitungsplattform und API für GPUs, CUDA (Compute Unified Device Architecture), verwendet CUDA-Kerne als Standard-Gleitkommaeinheit in NVIDIA-Grafikkarten. Diese Kerne waren in den letzten zehn Jahren ein entscheidendes Merkmal der NVIDIA-Grafikprozessor-Mikroarchitekturen und sind in jedem NVIDIA-Grafikprozessor vorhanden, der in dieser Zeit veröffentlicht wurde.
Jeder CUDA Kern führt Berechnungen durch und führt eine Operation pro Taktzyklus aus. Obwohl er nicht so leistungsfähig ist wie ein CPU-Kern, kann die parallele Nutzung mehrerer CUDA-Kerne für Deep Learning die Berechnungen erheblich beschleunigen. In diesem Artikel werden wir die Beziehung zwischen CUDA und Tensor Cores untersuchen, wie sie zusammenarbeiten, um High-Performance-Computing zu ermöglichen, und die einzigartigen Merkmale jeder NVIDIA GPU-Mikroarchitektur.
Vor der Einführung von Tensor Cores waren CUDA Cores die primäre Hardware für die Beschleunigung von Deep Learning. GPUs, die sich ausschließlich auf CUDA Kerne stützen, sind jedoch durch die Anzahl der verfügbaren Kerne und die Taktrate jedes Kerns eingeschränkt, da sie nur eine Berechnung pro Taktzyklus durchführen können. Um diesen Engpass zu überwinden, entwickelte NVIDIA den Tensor Core.
Der Tensor Core revolutionierte die Leistung von Grafikprozessoren, indem er die Fähigkeit zur Durchführung von Berechnungen mit gemischter Genauigkeit verbesserte und so die Menge der gleichzeitig verarbeiteten Daten erhöhte. In diesem Blog-Beitrag werden wir die Vorteile von Tensor Cores gegenüber CUDA Cores untersuchen und erläutern, wie sie zum High-Performance-Computing in den neuesten GPU-Mikroarchitekturen von NVIDIA beitragen.
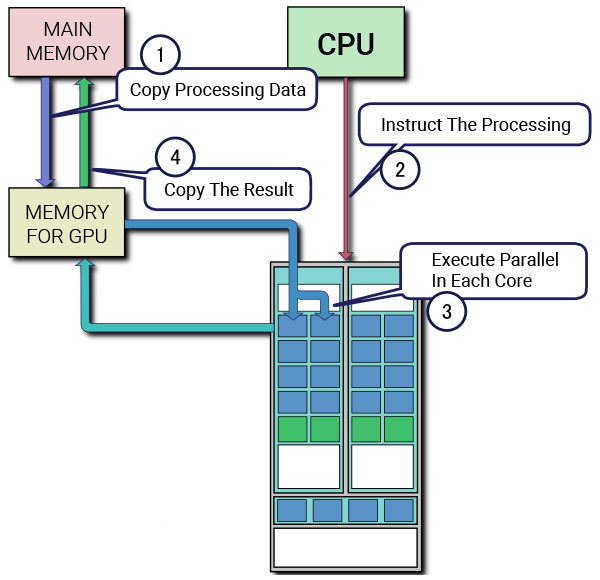
Was sind Tensor Cores?
Tensor Cores sind einzigartige Cores, die für das Training mit gemischter Präzision beim Deep Learning entwickelt wurden. Die erste Generation der Tensor Cores nutzt eine fusionierte Multiplikations-Additionsberechnung, die die Multiplikation und Addition von zwei 4×4 FP16-Matrizen zu einer 4×4 FP16- oder FP32-Matrix ermöglicht.
Die Berechnung mit gemischter Genauigkeit wird so genannt, weil die Eingangsmatrizen FP16 mit niedriger Genauigkeit sein können, während die Ausgangsmatrix eine FP32-Matrix mit höherer Genauigkeit ist, was zu schnelleren Berechnungen mit minimalem Verlust an Genauigkeit führt. Diese Funktion verbessert die Leistung von Deep-Learning-Modellen erheblich.
Im Zuge des technologischen Fortschritts haben neuere Mikroarchitekturen die Fähigkeiten von Tensor Cores erweitert, um noch ungenauere Computerzahlenformate zu unterstützen, wodurch die Berechnungen weiter beschleunigt werden, ohne dass die Wirksamkeit des Modells beeinträchtigt wird. Wir werden uns nun eingehender mit den technischen Aspekten von Tensor Cores und ihrem Beitrag zum Hochleistungsrechnen beim Deep Learning befassen.
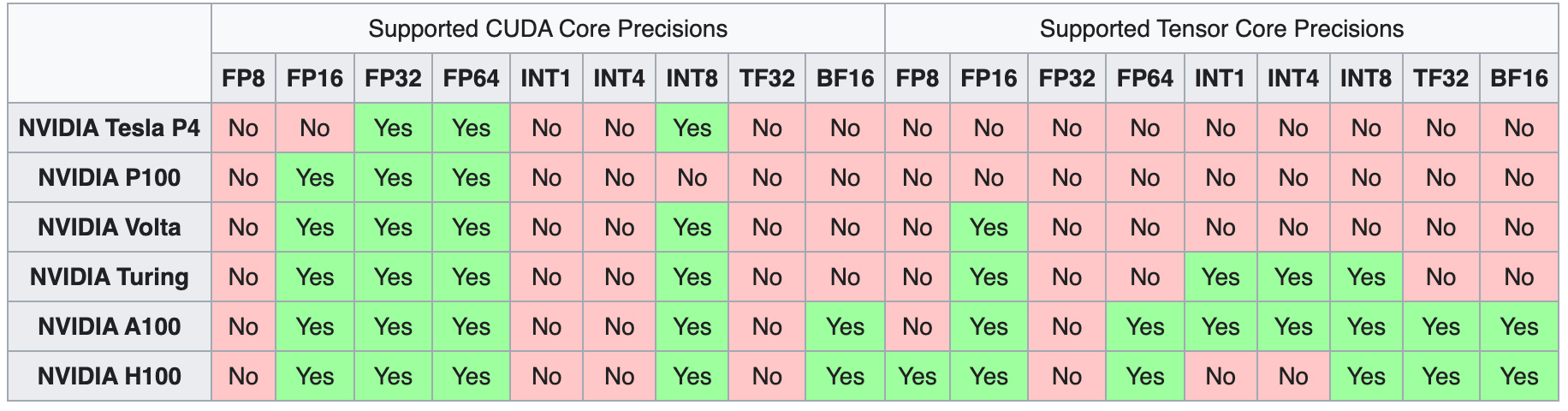
Die Einführung der ersten Generation von Tensor Cores begann mit der Volta-Mikroarchitektur, beginnend mit dem V100. Die nachfolgenden Generationen wurden mit zusätzlichen Formaten für die Rechengenauigkeit ausgestattet und erweiterten so die Bandbreite der durchführbaren Berechnungen.
Im folgenden Abschnitt werden wir die einzigartigen Merkmale und Verbesserungen jeder Mikroarchitektur in Bezug auf Tensor Cores und ihre Auswirkungen auf das High-Performance Computing im Deep Learning untersuchen.
Wie funktionieren Tensor Cores?
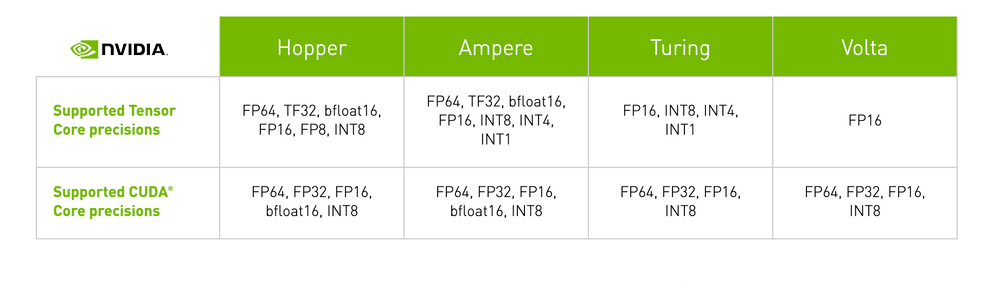
Mit jeder neuen Generation von GPU-Mikroarchitekturen wurden neue Methoden eingeführt, um die Leistung von Tensor-Core-Operationen zu verbessern. Diese Fortschritte haben die Palette der Computerzahlenformate erweitert, mit denen Tensor Cores arbeiten können, was zu einer erheblichen Steigerung des GPU-Durchsatzes mit jeder Iteration führt.
NVIDIA GPU-Mikroarchitektur der ersten Generation
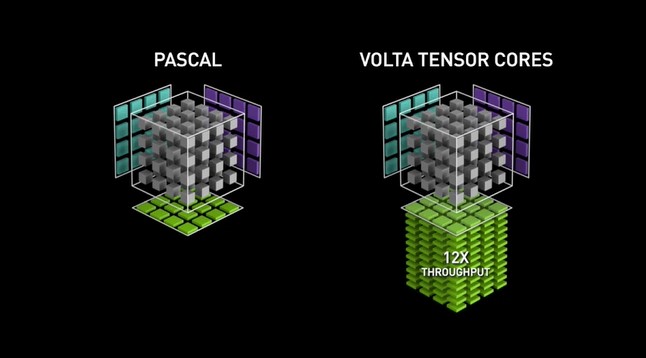
Die Volta-GPU-Mikroarchitektur markierte das Debüt der ersten Generation von Tensor Cores, die ein Training mit gemischter Präzision unter Verwendung des FP16-Zahlenformats ermöglichten. Diese Entwicklung führte zu einer massiven potenziellen Durchsatzsteigerung von bis zu 12x in TeraFLOPs. Das Flaggschiff V100 mit seinen 640 Kernen bot eine bis zu 5-mal höhere Leistungsgeschwindigkeit im Vergleich zur vorherigen Pascal-GPU-Generation.
NVIDIA GPU-Mikroarchitektur der zweiten Generation
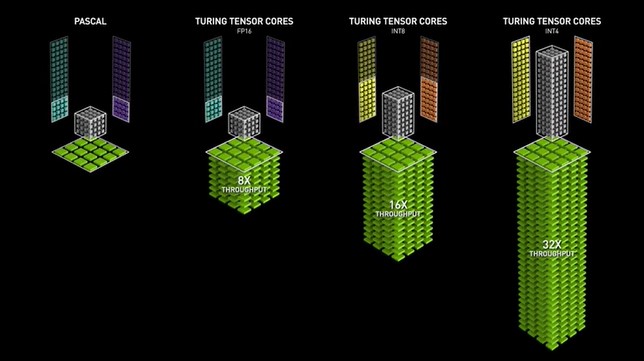
Mit den Turing-GPUs wurde die zweite Generation von Tensor Cores eingeführt, die neben FP16 auch Präzisionswerte wie Int8, Int4 und Int1 unterstützen. Diese Tensor Cores ermöglichen Trainingsoperationen mit gemischter Präzision und beschleunigen die GPU-Leistung im Vergleich zu Pascal-GPUs um das bis zu 32-fache. Die Turing-GPUs verfügen außerdem über Ray-Tracing-Cores, die grafische Visualisierungseigenschaften wie Licht und Ton in 3D-Umgebungen verbessern.
NVIDIA GPU-Mikroarchitektur der dritten Generation
Die Ampere-GPUs sind mit der dritten Generation von Tensor Cores ausgestattet. Durch die Erweiterung der Rechenleistung auf FP64-, TF32- und bfloat16-Präzisionen beschleunigen Ampere-GPUs Deep-Learning-Trainings- und Inferenzaufgaben noch weiter. Mit Funktionen wie der Spezialisierung auf spärliche Matrizenmathematik, NVLink der dritten Generation und Ray-Tracing-Cores der dritten Generation sind die Ampere-GPUs - insbesondere das Rechenzentrum A100.
Budgetbewusste Anwender können die Vorteile der leistungsstarken Ampere-Mikroarchitektur und der Tensor-Cores der dritten Generation auch über die Workstation-GPU-Linie nutzen, z. B. die A4000, A5000 und A6000. Die Implementierung der automatischen gemischten Präzision kann das Training mit nur wenigen Codezeilen um das Doppelte beschleunigen.
Die Ampere-Mikroarchitektur bietet fortschrittliche Funktionen wie die Spezialisierung auf spärliche Matrixmathematik, NVLink der dritten Generation für blitzschnelle Multi-GPU-Interaktionen und Ray-Tracing-Kerne der dritten Generation.
Die Workstation-GPU-Linie, wie die A4000, A5000 und A6000, bietet jedoch eine erschwinglichere Möglichkeit, auf die leistungsstarke Ampere-Mikroarchitektur und ihre Tensor-Cores der dritten Generation zuzugreifen, wenn das Budget knapp ist.
NVIDIA GPU-Mikroarchitektur der vierten Generation
Im September 2022 stellte NVIDIA die Hopper-Mikroarchitektur vor, die die vierte Generation von Tensor-Cores enthält. Diese Cores bieten durch die Unterstützung von FP8-Präzisionsformaten eine höhere Leistungsfähigkeit, die laut NVIDIA große Sprachmodelle um das bis zu 30-fache gegenüber der vorherigen Generation beschleunigen kann. Die H100 ist der erste Grafikprozessor, der mit diesen neuen Tensor Cores ausgestattet ist, was sie zu einer leistungsstarken Option für alle macht, die auf der Suche nach der neuesten Deep-Learning-Technologie sind.
Schlussfolgerung
Die Fortschritte in der GPU-Technologie sind eng mit der Entwicklung der Tensor Core-Technologie verbunden. Diese Kerne ermöglichen hochleistungsfähiges Mixed-Precision-Training und haben Volta-, Turing- und Ampere-GPUs zu den bevorzugten Maschinen für die KI-Entwicklung werden lassen. Wie in diesem Artikel beschrieben, ist der Fortschritt von einer GPU-Generation zur nächsten durch Verbesserungen der Tensor Core-Funktionen gekennzeichnet.
Das Verständnis der Fähigkeiten und Unterschiede zwischen den Tensor Cores ist entscheidend, um den erheblichen Leistungsschub zu verstehen, den jede nachfolgende GPU-Generation für Deep-Learning-Aufgaben bringt. Durch die Nutzung dieser leistungsstarken Kerne hat jede Generation, von Volta bis Hopper, den Weg für die Verarbeitung immer größerer Datenmengen in noch nie dagewesener Geschwindigkeit geebnet.










