Dans cet article:
- Comprendre les cœurs de tenseur
- Que sont les cœurs CUDA ?
- Qu'est-ce qu'un Tensor Cores ?
- Comment fonctionnent les Tensor Cores ?
- Microarchitecture GPU NVIDIA de première génération
- Microarchitecture GPU NVIDIA de deuxième génération
- Microarchitecture GPU NVIDIA de troisième génération
- Microarchitecture GPU NVIDIA de quatrième génération
- Conclusion

Comprendre les cœurs de tenseur
Le Tensor Core de Nvidia est une technologie cruciale dans les dernières versions de la microarchitecture GPU. À chaque génération, ces sous-unités de traitement spécialisées ont progressé depuis leur introduction dans Volta, fournissant un coup de pouce significatif aux performances du GPU grâce à l'apprentissage automatique de la précision mixte.
Cet article présente un résumé des capacités du Tensor Core dans les séries Volta, Turing et Ampere des GPU NVIDIA. À la fin de cet article, les lecteurs auront une compréhension claire des différents types de cœurs de GPU NVIDIA, de la façon dont les Tensor Cores facilitent l'entraînement en précision mixte pour l'apprentissage profond, de la façon de distinguer les performances des Tensor Cores de chaque microarchitecture, et de la façon de reconnaître les GPU équipés de Tensor Cores.
Que sont les cœurs CUDA ?
Pour approfondir l'architecture et l'utilité des Tensor Cores, il est essentiel de comprendre ce que sont les cœurs CUDA. La plate-forme de traitement parallèle et l'API propriétaires de NVIDIA pour les GPU, CUDA (Compute Unified Device Architecture), utilisent les cœurs CUDA comme unité de virgule flottante standard dans les cartes graphiques NVIDIA. Ces cœurs ont été une caractéristique déterminante des microarchitectures de GPU NVIDIA au cours de la dernière décennie, puisqu'ils sont présents dans tous les GPU NVIDIA commercialisés au cours de cette période.
Chaque cœur CUDA effectue des calculs et exécute une opération par cycle d'horloge. Bien qu'il ne soit pas aussi puissant qu'un cœur de CPU, l'utilisation de plusieurs cœurs CUDA en parallèle pour l'apprentissage profond permet d'accélérer considérablement les calculs. Dans cet article, nous allons explorer la relation entre CUDA et les Tensor Cores, la façon dont ils fonctionnent ensemble pour permettre un calcul de haute performance et les caractéristiques uniques de chaque microarchitecture de GPU NVIDIA.
Avant l'introduction des Tensor Cores, les cœurs CUDA étaient le principal matériel utilisé pour accélérer l'apprentissage profond. Cependant, les GPU qui s'appuient uniquement sur les cœurs CUDA sont limités par le nombre de cœurs disponibles et la vitesse d'horloge de chaque cœur, car ils ne peuvent traiter qu'un seul calcul par cycle d'horloge. Pour surmonter ce goulot d'étranglement, NVIDIA a développé le Tensor Core.
Le Tensor Core a révolutionné les performances des GPU en améliorant la capacité à effectuer des calculs en précision mixte, augmentant ainsi la quantité de données pouvant être traitées simultanément. Dans ce billet de blog, nous allons explorer les avantages des Tensor Cores par rapport aux cœurs CUDA et la façon dont ils contribuent au calcul haute performance dans les dernières microarchitectures de GPU de NVIDIA.
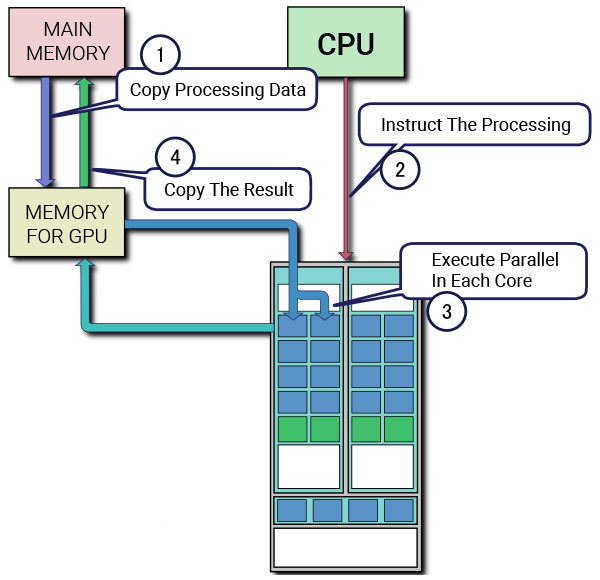
Qu'est-ce qu'un Tensor Cores ?
Les Tensor Cores sont des cœurs uniques conçus pour permettre un entraînement de précision mixte dans l'apprentissage profond. La première génération de Tensor Cores utilise un calcul de multiplication et d'addition fusionné, permettant la multiplication et l'addition de deux matrices 4×4 FP16 à une matrice 4×4 FP16 ou FP32.
Le calcul de précision mixte est appelé ainsi parce que les matrices d'entrée peuvent être de faible précision FP16, tandis que la matrice de sortie est de plus grande précision FP32, ce qui permet des calculs plus rapides avec une perte de précision minimale. Cette caractéristique améliore considérablement les performances des modèles d'apprentissage profond.
Au fur et à mesure des progrès technologiques, de nouvelles microarchitectures ont étendu les capacités des Tensor Cores pour prendre en charge des formats de nombres informatiques encore moins précis, ce qui accélère encore les calculs tout en préservant l'efficacité du modèle. Nous allons maintenant approfondir les aspects techniques des Tensor Cores et leurs contributions au calcul de haute performance dans l'apprentissage profond.
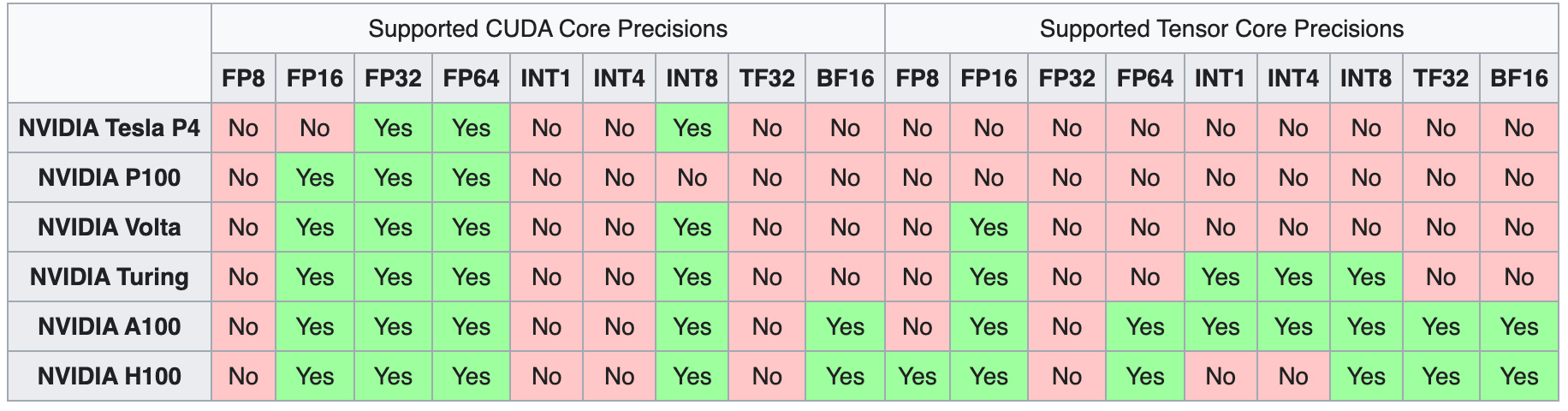
L'introduction de la première génération de Tensor Cores a commencé avec la microarchitecture Volta, en commençant par le V100. Au fur et à mesure que les générations suivantes sont apparues, elles ont été équipées de formats de précision supplémentaires pour les nombres informatiques, élargissant ainsi la gamme des calculs pouvant être effectués.
Dans la section suivante, nous allons explorer les caractéristiques et améliorations uniques de chaque microarchitecture en ce qui concerne les Tensor Cores et leur impact sur le calcul haute performance dans le domaine de l'apprentissage profond.
Comment fonctionnent les Tensor Cores ?
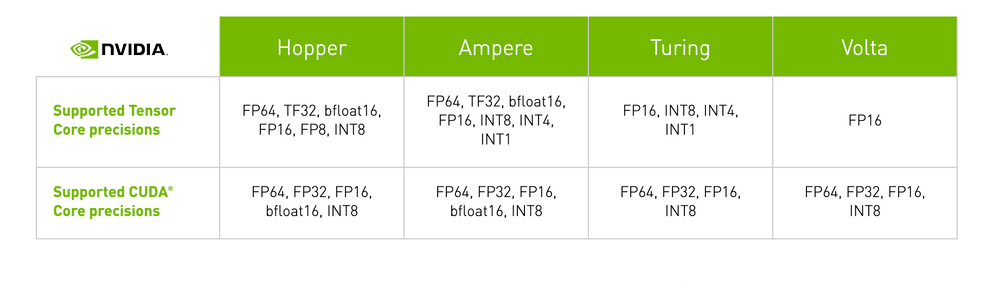
Avec chaque nouvelle génération de microarchitecture GPU, de nouvelles méthodologies ont été introduites pour améliorer les performances des opérations des Tensor Cores. Ces avancées ont élargi la gamme des formats de nombres informatiques sur lesquels les Tensor Cores peuvent fonctionner, ce qui se traduit par une augmentation significative du débit du GPU à chaque itération.
Microarchitecture GPU NVIDIA de première génération
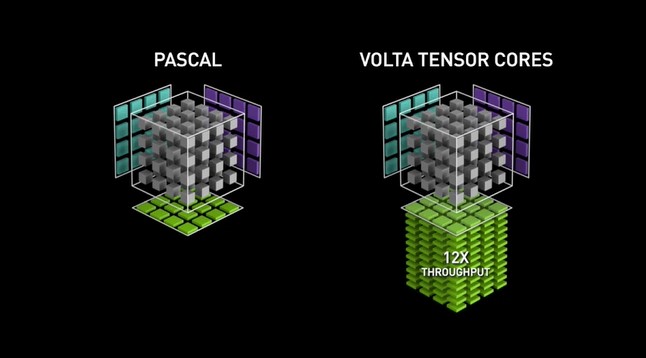
La microarchitecture du GPU Volta a marqué le début de la première génération de Tensor Cores, qui a facilité l'apprentissage de la précision mixte en utilisant le format de nombre FP16. Ce développement a permis d'augmenter considérablement le débit potentiel, jusqu'à 12 fois en téraFLOPs. Le modèle phare V100, avec ses 640 cœurs, offre des performances jusqu'à cinq fois supérieures à celles de la génération précédente de GPU Pascal.
Microarchitecture GPU NVIDIA de deuxième génération
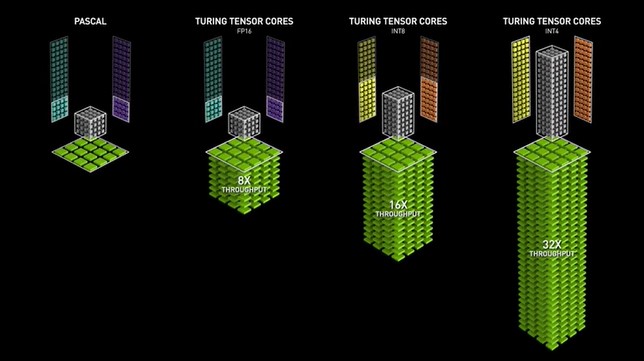
Les GPU Turing ont introduit la deuxième génération de Tensor Cores, prenant en charge des précisions telles que Int8, Int4 et Int1 en plus de FP16. Ces Tensor Cores permettent des opérations d'apprentissage à précision mixte, accélérant les performances du GPU jusqu'à 32 fois par rapport aux GPU Pascal. Les GPU Turing sont également dotés de cœurs Ray Tracing, qui améliorent les propriétés de visualisation graphique telles que la lumière et le son dans les environnements 3D.
Microarchitecture GPU NVIDIA de troisième génération
La gamme de GPU Ampere présente la troisième génération de Tensor Cores. En étendant la capacité de calcul aux précisions FP64, TF32 et bfloat16, les GPU Ampere accélèrent encore davantage les tâches de formation et d'inférence en matière d'apprentissage profond. Grâce à des fonctionnalités telles que la spécialisation avec les mathématiques des matrices éparses, NVLink de troisième génération et les cœurs Ray Tracing de troisième génération, les GPU Ampere - en particulier le centre de données A100.
Les utilisateurs soucieux de leur budget peuvent également profiter de la puissante microarchitecture Ampere et des Tensor Cores de troisième génération grâce à la gamme de GPU pour stations de travail, tels que les A4000, A5000 et A6000. L'implémentation de la précision mixte automatique peut accélérer la formation d'un facteur 2 supplémentaire avec seulement quelques lignes de code.
La microarchitecture Ampere est dotée de fonctions avancées telles que la spécialisation en mathématiques des matrices éparses, la troisième génération de NVLink pour des interactions multi-GPU rapides comme l'éclair et les cœurs de Ray Tracing de troisième génération.
Toutefois, pour les personnes disposant d'un budget limité, la gamme de GPU pour stations de travail, tels que les modèles A4000, A5000 et A6000, offre un moyen plus abordable d'accéder à la puissante microarchitecture Ampere et à ses cœurs tensoriels de troisième génération.
Microarchitecture GPU NVIDIA de quatrième génération
En septembre 2022, NVIDIA a lancé la microarchitecture Hopper, avec la quatrième génération de Tensor Cores. Ces cœurs offrent des capacités accrues en prenant en charge les formats de précision FP8, ce qui, selon NVIDIA, permet d'accélérer les grands modèles de langage jusqu'à 30 fois par rapport à la génération précédente. Le H100 est le premier GPU à intégrer ces nouveaux Tensor Cores, ce qui en fait une option puissante pour ceux qui recherchent la dernière technologie de deep learning.
Conclusion
Les progrès de la technologie GPU sont étroitement liés à l'évolution de la technologie Tensor Core. Ces cœurs permettent un entraînement de précision mixte de haute performance et ont permis aux GPU Volta, Turing et Ampere de devenir les machines préférées pour le développement de l'IA. Comme le souligne cet article, la progression d'une génération de GPU à l'autre est marquée par l'amélioration des capacités des Tensor Core.
Il est essentiel de comprendre les capacités et les différences entre les Tensor Cores pour saisir l'augmentation significative des performances que chaque génération de GPU apporte aux tâches d'apprentissage en profondeur. En tirant parti de ces puissants cœurs, chaque génération, de Volta à Hopper, a ouvert la voie au traitement de quantités de données de plus en plus massives à une vitesse sans précédent.










