Dans cet article:
NVIDIA Jetson AGX Xavier pour une nouvelle ère de l'IA en robotique
En apportant des niveaux de calcul qui changent la donne, NVIDIA Jetson AGX Xavier fournit 32 TeraOps pour une nouvelle ère de l'IA dans la robotique.
Jetson AGX Xavier, la solution embarquée la plus aboutie au monde pour les développeurs d'IA, est désormais livrée sous forme de modules de production autonomes par NVIDIA. Membre des systèmes AGX de NVIDIA pour les machines autonomes, Jetson AGX Xavier est idéal pour déployer l'IA avancée et la vision par ordinateur à la périphérie, permettant aux plates-formes robotiques sur le terrain d'avoir des performances de niveau station de travail et la capacité de fonctionner de manière totalement autonome sans dépendre de l'intervention humaine et de la connectivité avec le cloud. Les machines intelligentes propulsées par Jetson AGX Xavier ont la liberté d'interagir et de naviguer en toute sécurité dans leur environnement, sans être gênées par des terrains complexes et des obstacles dynamiques, accomplissant des tâches du monde réel en toute autonomie. Il s'agit notamment de la livraison de colis et de l'inspection industrielle qui nécessitent des niveaux avancés de perception et d'inférence en temps réel. Premier ordinateur au monde conçu spécifiquement pour la robotique et l'informatique de pointe, les performances élevées de Jetson AGX Xavier peuvent prendre en charge les algorithmes d'odométrie visuelle, de fusion de capteurs, de localisation et de cartographie, de détection d'obstacles et de planification de trajectoire essentiels pour les robots de la prochaine génération. La photo ci-dessous montre les modules de calcul de production désormais disponibles dans le monde entier. Les développeurs peuvent désormais commencer à déployer de nouvelles machines autonomes en volume.
 Module de calcul embarqué Jetson AGX Xavier avec plaque de transfert thermique (TTP), 100x87mm
Module de calcul embarqué Jetson AGX Xavier avec plaque de transfert thermique (TTP), 100x87mm
Dernière génération de la famille Jetson AGX de NVIDIA, leader sur le marché des ordinateurs Linux embarqués à hautes performances, Jetson AGX Xavier offre des performances de station de travail GPU avec un pic de calcul inégalé de 32 TeraOPS (TOPS) et 750 Gbps d'E/S à haut débit dans un format compact de 100x87 mm. Les utilisateurs peuvent configurer les modes de fonctionnement à 10W, 15W et 30W selon les besoins de leurs applications. Jetson AGX Xavier place la barre très haut en matière de densité de calcul, d'efficacité énergétique et de capacités d'inférence IA déployables à la périphérie, ce qui permet de créer des machines intelligentes de niveau supérieur dotées de capacités autonomes de bout en bout.
Jetson alimente l'IA derrière de nombreux robots et machines autonomes parmi les plus avancés au monde en utilisant l'apprentissage profond et la vision par ordinateur tout en se concentrant sur la performance, l'efficacité et la programmabilité. Jetson AGX Xavier, dont le schéma figure ci-dessous, comprend plus de 9 milliards de transistors et repose sur le système sur puce (SoC) le plus complexe jamais créé. La plate-forme comprend un GPU intégré NVIDIA Volta à 512 cœurs dont 64 cœurs de tenseur, un CPU 64 bits NVIDIA Carmel ARMv8.2 à 8 cœurs, 16 Go de LPDDR4x 256 bits, deux moteurs NVIDIA Deep Learning Accelerator (DLA), un moteur NVIDIA Vision Accelerator, des codecs vidéo HD, 128 Gbps d'ingestion de caméra dédiée et 16 voies d'expansion PCIe Gen 4. La bande passante mémoire sur l'interface 256 bits pèse 137 Go/s, tandis que les moteurs DLA déchargent l'inférence des réseaux neuronaux profonds (DNN). Le SDK JetPack 4.1.1 de NVIDIA pour Jetson AGX Xavier comprend CUDA 10.0, cuDNN 7.3 et TensorRT 5.0, fournissant ainsi une pile logicielle complète pour l'IA.
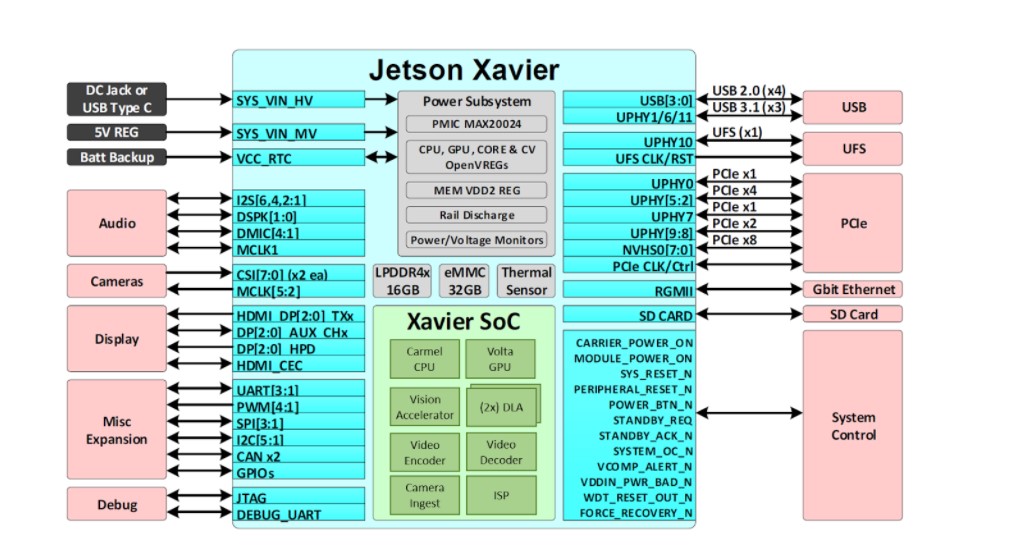 La Jetson AGX Xavier offre un riche ensemble d'E/S à grande vitesse
La Jetson AGX Xavier offre un riche ensemble d'E/S à grande vitesse
Cela permet aux développeurs de déployer une IA accélérée dans des applications telles que la robotique, l'analyse vidéo intelligente, les instruments médicaux, les périphériques IoT intégrés, etc. Comme ses prédécesseurs Jetson TX1 et TX2, Jetson AGX Xavier utilise un paradigme de système sur module (SoM). Tout le traitement est contenu à bord du module de calcul et les E/S à grande vitesse vivent sur un support d'éclatement ou un boîtier qui est fourni par un connecteur carte à carte haute densité. En encapsulant ainsi les fonctionnalités sur le module, les développeurs peuvent facilement intégrer le Jetson Xavier dans leurs propres conceptions. NVIDIA a publié une documentation complète et des fichiers de conception de référence à télécharger pour les concepteurs intégrés qui créent leurs propres appareils et plates-formes à l'aide de Jetson AGX Xavier.
Veillez à consulter la fiche technique du module Jetson AGX Xavier et le guide de conception du produit OEM Jetson AGX Xavier pour connaître toutes les caractéristiques du produit énumérées dans le tableau ci-dessous, ainsi que les spécifications électromécaniques, le brochage du module, le séquençage de l'alimentation et les directives de routage des signaux.
|
Module NVIDIA Jetson AGX Xavier |
|
|
CPU |
nVIDIA Carmel 64-bit ARMv8.2 à 8 cœurs @ 2265MHz |
|
GPU |
nVIDIA Volta 512 cœurs à 1377 MHz avec 64 TensorCores |
|
DL |
Deux accélérateurs d'apprentissage profond (DLA) NVIDIA |
|
Mémoire et stockage |
16 Go LPDDR4x 256 bits @ 2133 MHz | 137 Go/s 32 Go eMMC 5.1 |
|
Vision |
(2x) Accélérateur Vision VLIW 7 voies |
|
Encodeur* |
(4x) 4Kp60 | (8x) 4Kp30 | (16x) 1080p60 | (32x) 1080p30Débit maximal jusqu'à (2x) 1000MP/s - H.265 Main |
|
H.265* |
(2x) 8Kp30 | (6x) 4Kp60 | (12x) 4Kp30 | (26x) 1080p60 | (52x) 1080p30Débit maximal jusqu'à (2x) 1500MP/s - H.265 Principal |
|
Caméra principale† |
(16x) voies MIPI CSI-2, (8x) voies SLVS-EC ; jusqu'à 6 flux de capteurs actifs et 36 canaux virtuels |
|
Écran |
(3x) eDP 1.4 / DP 1.2 / HDMI 2.0 @ 4Kp60 |
|
Ethernet |
10/100/1000 BASE-T Ethernet + MAC + interface RGMII |
|
USB |
(3x) USB 3.1 + (4x) USB 2.0 |
|
PCIe†† |
(5x) Contrôleurs PCIe Gen 4 | 1×8, 1×4, 1×2, 2×1 |
|
CAN |
Contrôleur de bus CAN double |
|
E/S diverses |
UART, SPI, I2C, I2S, GPIOs |
|
Socle |
connecteur carte à carte 699 broches, 100x87mm avec 16mm de hauteur en Z |
|
Thermique‡ |
-25°C à 80°C |
|
Puissance |
profils 10W / 15W / 30W, entrée 9.0V-20VDC |
|
*Nombre maximum de flux simultanés jusqu'au débit global. Codecs vidéo pris en charge : H.265, H.264, VP9Veuillez vous référer à la fiche technique du module Jetson AGX Xavier §1.6.1 et §1.6.2 pour les spécifications spécifiques des codecs et des profils.+MIPI CSI-2, jusqu'à 40 Gbps en D-PHY V1.2 ou 109 Gbps en CPHY v1.1SLVS-EC, jusqu'à 18,4 Gbps++(3x) Root Port + Endpoint controllers et (2x) Root Port controllers+Température de fonctionnement, température de jonction maximale de la plaque de transfert thermique (TTP). |
|
La Jetson AGX Xavier comprend plus de 750 Gbps d'E/S haute vitesse, offrant une quantité extraordinaire de bande passante pour le streaming de capteurs et de périphériques haute vitesse. C'est l'un des premiers dispositifs embarqués à prendre en charge la norme PCIe Gen 4, offrant 16 voies sur cinq contrôleurs PCIe Gen 4, dont trois peuvent fonctionner en mode port racine ou point d'extrémité. les 16 voies MIPI CSI-2 peuvent être connectées à quatre caméras à 4 voies, six caméras à 2 voies, six caméras à 1 voie, ou une combinaison de ces configurations jusqu'à six caméras, avec 36 canaux virtuels permettant de connecter plus de caméras simultanément en utilisant l'agrégation de flux. Les autres E/S à haut débit comprennent trois ports USB 3.1, SLVS-EC, UFS, et RGMII pour Gigabit Ethernet. Les développeurs ont désormais accès au logiciel NVIDIA JetPack 4.1.1 Developer Preview pour Jetson AGX Xavier, dont la liste figure dans le tableau ci-dessous. Le Developer Preview inclut Linux For Tegra (L4T) R31.1 Board Support Package (BSP) avec prise en charge du noyau Linux 4.9 et d'Ubuntu 18.04 sur la cible. Du côté du PC hôte, JetPack 4.1.1 prend en charge Ubuntu 16.04 et Ubuntu 18.04.
|
NVIDIA JetPack 4.1.1 Developer Preview Release (en anglais) |
|
|
L4T R31.0.1 (Linux K4.9) |
Ubuntu 18.04 LTS aarch64 |
|
CUDA Toolkit 10.0 |
cuDNN 7.3 |
|
TensorRT 5.0 GA |
GStreamer 1.14.1 |
|
VisionWorks 1.6 |
OpenCV 3.3.1 |
|
OpenGL 4.6 / GLES 3.2 |
Vulkan 1.1 |
|
NVIDIA Nsight Systems 2018.1 |
NVIDIA Nsight Graphics 2018.6 |
|
API multimédia R31.1 |
Argus 0.97 Camera API |
Composants logiciels inclus dans JetPack 4.1.1 Developer Preview et L4T BSP pour Jetson AGX Xavier
La version 4.1.1 Developer Preview de JetPack permet aux développeurs de commencer immédiatement à prototyper des produits et des applications avec Jetson AGX Xavier en vue d'un déploiement en production. NVIDIA continuera d'apporter des améliorations à JetPack avec de nouvelles fonctionnalités et des optimisations de performances. Veuillez lire les notes de mise à jour pour connaître les points forts et l'état du logiciel de cette version.
GPU Volta
Le GPU Volta intégré à la Jetson AGX Xavier, illustré à la figure 3, fournit 512 cœurs CUDA et 64 cœurs Tensor pour un calcul de 11 TFLOPS FP16 ou 22 TOPS INT8, avec une fréquence d'horloge maximale de 1,37 GHz. Il prend en charge CUDA 10 avec une capacité de calcul de sm_72. Le GPU comprend huit multiprocesseurs de streaming Volta (SM) avec 64 cœurs CUDA et 8 cœurs de tenseur par SM Volta. Chaque SM Volta comprend un cache L1 de 128 Ko, soit 8 fois plus que les générations précédentes. Les SM partagent un cache L2 de 512 Ko et offrent un accès quatre fois plus rapide que les générations précédentes.
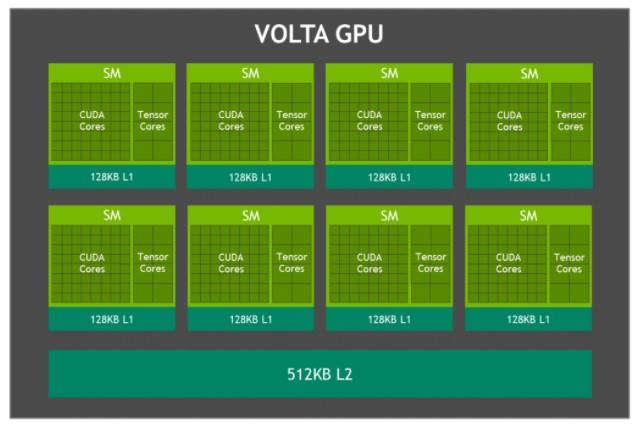 Schéma fonctionnel du GPU Jetson AGX Xavier Volta
Schéma fonctionnel du GPU Jetson AGX Xavier Volta
Chaque SM se compose de 4 blocs de traitement distincts appelés SMP (streaming multiprocessor partitions), chacun comprenant son propre cache d'instructions L0, son planificateur de warp, son unité de répartition et son fichier de registre, ainsi que des cœurs CUDA et des cœurs Tensor. Avec deux fois plus de SMP par SM que Pascal, le Volta SM offre une meilleure concurrence et prend en charge davantage de threads, de warps et de blocs de threads en vol.
Tensor Cores
Les NVIDIA Tensor Cores sont des unités programmables de multiplication et d'accumulation de matrices fusionnées qui s'exécutent simultanément avec les cœurs CUDA. Les Tensor Cores implémentent les nouvelles instructions HMMA (Half-Precision Matrix Multiply and Accumulate) et IMMA (Integer Matrix Multiply and Accumulate) en virgule flottante pour accélérer les calculs d'algèbre linéaire denses, le traitement du signal et l'inférence d'apprentissage profond.
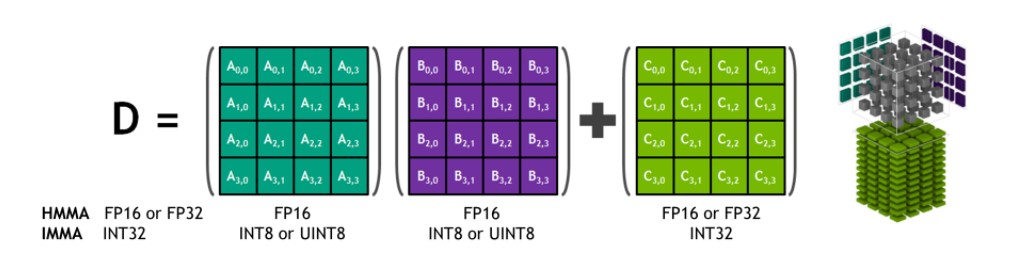
Multiplication et accumulation de matrices 4x4x4 HMMA/IMMA de Tensor Core
Les entrées de multiplication de matrice A et B sont des matrices FP16 pour les instructions HMMA, tandis que les matrices d'accumulation C et D peuvent être des matrices FP16 ou FP32. Pour l'IMMA, l'entrée de multiplication de la matrice A est une matrice INT8 ou INT16 signée ou non signée, B est une matrice INT8 signée ou non signée, et les matrices d'accumulation C et D sont des matrices INT32 signées. La plage de précision et de calcul est donc suffisante pour éviter les conditions de débordement et de sous-débordement pendant l'accumulation interne.
Les bibliothèques NVIDIA, dont cuBLAS, cuDNN et TensorRT, ont été mises à jour pour utiliser HMMA et IMMA en interne, ce qui permet aux programmeurs de profiter facilement des gains de performance inhérents aux Tensor Cores. Les utilisateurs peuvent également accéder directement aux opérations des Tensor Cores au niveau du warp via une nouvelle API exposée dans l'espace de noms wmma et l'en-tête mma.h inclus dans CUDA 10. L'interface au niveau du warp permet de mapper des matrices de taille 16×16, 32×8 et 8×32 sur l'ensemble des 32 threads par warp.
Accélérateur d'apprentissage profond
La Jetson AGX Xavier est équipée de deux moteurs NVIDIA Deep Learning Accelerator (DLA), illustrés dans le diagramme ci-dessous, qui déchargent l'inférence des réseaux neuronaux convolutifs (CNN) à fonction fixe. Ces moteurs améliorent l'efficacité énergétique et libèrent le GPU pour exécuter des réseaux plus complexes et des tâches dynamiques mises en œuvre par l'utilisateur. L'architecture matérielle des DLA de NVIDIA est open-source et disponible sur le site NVDLA.org. Chaque DLA a des performances allant jusqu'à 5 TOPS INT8 ou 2,5 TFLOPS FP16 avec une consommation d'énergie de seulement 0,5-1,5W. Les DLA prennent en charge l'accélération des couches CNN telles que la convolution, la déconvolution, les fonctions d'activation, la mise en commun min/max/moyenne, la normalisation de la réponse locale et les couches entièrement connectées.
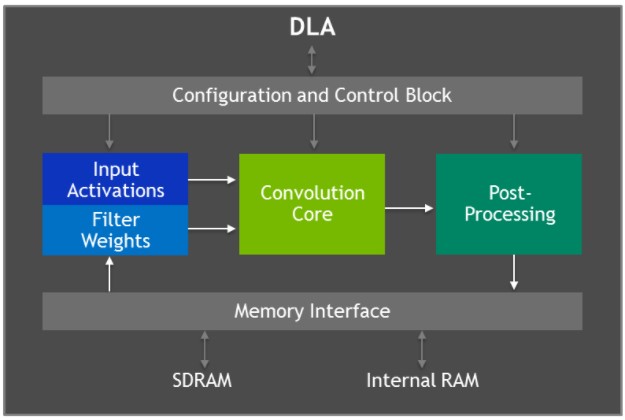 Schéma fonctionnel de l'architecture de l'accélérateur d'apprentissage profond (DLA)
Schéma fonctionnel de l'architecture de l'accélérateur d'apprentissage profond (DLA)
Le matériel de l'accélérateur d'apprentissage profond se compose des éléments suivants :
- Cœur de convolution - moteur de convolution haute performance optimisé.
- Single Data Processor - moteur de recherche à point unique pour les fonctions d'activation.
- Processeur de données planaires - moteur de calcul de moyenne planaire pour la mise en commun.
- Channel Data Processor - moteur de calcul de moyenne multicanal pour les fonctions de normalisation avancées.
- Mémoire dédiée et moteurs de remodelage des données - accélération de la transformation de mémoire à mémoire pour les opérations de remodelage et de copie des tenseurs.
Les développeurs programment des moteurs DLA utilisant TensorRT 5.0 pour effectuer des inférences sur des réseaux, y compris la prise en charge d'AlexNet, GoogleNet et ResNet-50. Pour les réseaux qui utilisent des configurations de couches non prises en charge par les DLA, TensorRT fournit une solution de repli GPU pour les couches qui ne peuvent pas être exécutées sur les DLA. Le JetPack 4.0 Developer Preview limite la précision des DLA au mode FP16 dans un premier temps, avec une précision INT8 et des performances accrues pour les DLA dans une prochaine version de JetPack.
TensorRT 5.0 ajoute les API suivantes à son interface IBuilder pour activer les DLA :
- Set Device Type() et set Default Device Type() pour sélectionner GPU, DLA_0, ou DLA_1 pour l'exécution d'une couche particulière, ou pour toutes les couches du réseau par défaut.
- Can Run On DLA() pour vérifier si une couche peut s'exécuter sur le DLA tel qu'il est configuré.
- Get Max DLA Batch Size() pour récupérer la taille maximale du lot que DLA peut supporter.
- Allow GPU Fallback() pour permettre au GPU d'exécuter des couches que DLA ne supporte pas.
Benchmarks d'inférence en apprentissage profond
Nous avons publié les résultats des tests d'inférence d'apprentissage profond pour Jetson AGX Xavier sur des DNN communs tels que les variantes de ResNet, GoogleNet et VGG. Nous avons exécuté ces tests pour Jetson AGX Xavier en utilisant la version 4.1.1 Developer Preview de JetPack avec TensorRT 5.0 sur les moteurs GPU et DLA de Jetson AGX Xavier. Le GPU et deux DLA ont exécuté les mêmes architectures de réseaux simultanément en précision INT8 et FP16 respectivement, la performance globale étant rapportée pour chaque configuration. Le GPU et les DLA peuvent exécuter simultanément différents réseaux ou modèles de réseaux dans des cas d'utilisation réels, remplissant des fonctions uniques les uns à côté des autres en parallèle ou dans un pipeline de traitement. L'utilisation de la précision INT8 par rapport à la précision FP32 dans TensorRT entraîne une perte de précision de 1 % ou moins.
Examinons tout d'abord les résultats de ResNet-18 FCN (Fully Convolutional Network), un modèle Full-HD d'une résolution de 2048×1024 utilisé pour la segmentation sémantique. la segmentation fournit une classification par pixel pour des tâches telles que la détection d'espace libre et la cartographie d'occupation, et est représentative des charges de travail d'apprentissage profond calculées par des machines autonomes pour la perception, la planification du chemin et la navigation. Le graphique ci-dessous montre le débit mesuré de l'exécution de ResNet-18 FCN sur Jetson AGX Xavier par rapport à Jetson TX2.
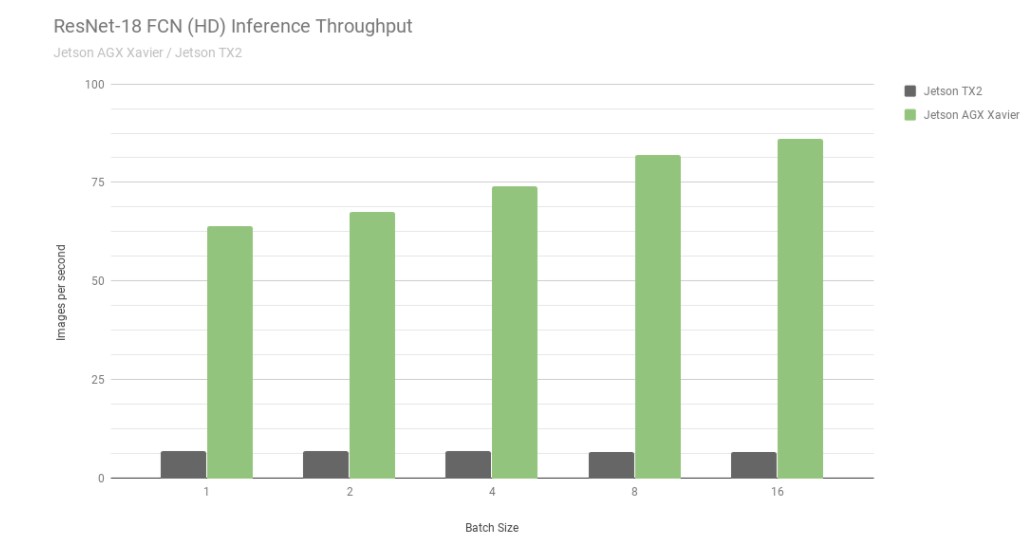 Débit d'inférence de ResNet-18 FCN sur Jetson AGX Xavier et Jetson TX2
Débit d'inférence de ResNet-18 FCN sur Jetson AGX Xavier et Jetson TX2
La Jetson AGX Xavier atteint actuellement des performances jusqu'à 13 fois supérieures à celles de la Jetson TX2 pour l'inférence ResNet-18 FCN. NVIDIA continuera à publier des optimisations logicielles et des améliorations de fonctionnalités dans JetPack qui permettront d'améliorer encore les performances et les caractéristiques énergétiques au fil du temps. notez que les listes complètes des résultats des tests de référence indiquent les performances de ResNet-18 FCN pour la Jetson AGX Xavier jusqu'à une taille de lot de 32, mais dans le graphique ci-dessous, nous n'indiquons que jusqu'à une taille de lot de 16, car la Jetson TX2 est capable d'exécuter ResNet-18 FCN jusqu'à une taille de lot de 16.
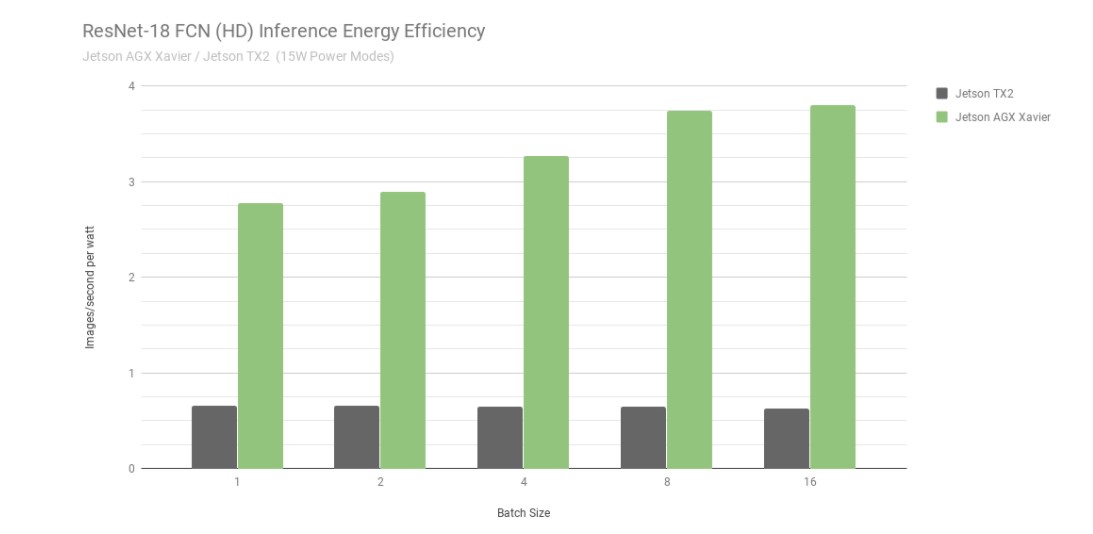
Efficacité énergétique de l'inférence ResNet-18 FCN sur Jetson AGX Xavier et Jetson TX2
Si l'on considère l'efficacité énergétique en utilisant les images traitées par seconde et par watt, la Jetson AGX Xavier est actuellement jusqu'à 6 fois plus économe en énergie que la Jetson TX2 à ResNet-18 FCN. Nous avons calculé l'efficacité en mesurant la consommation totale du module à l'aide des moniteurs de tension et de courant INA embarqués, y compris l'utilisation de l'énergie du CPU, du GPU, des DLA, de la mémoire, de l'alimentation diverse du SoC, des E/S et des pertes d'efficacité du régulateur sur tous les rails. Les deux Jetson ont fonctionné en mode d'alimentation 15W. Les Jetson AGX Xavier et JetPack sont livrés avec des profils d'alimentation prédéfinis configurables pour 10W, 15W et 30W, commutables en cours d'exécution à l'aide de l'outil de gestion de l'alimentation nvpmodel. Les utilisateurs peuvent également définir leurs propres profils personnalisés avec des horloges différentes et des paramètres de gouverneur DVFS (Dynamic Voltage and Frequency Scaling) qui ont été adaptés pour obtenir les meilleures performances pour les applications individuelles.
Ensuite, comparons les benchmarks Jetson AGX Xavier sur les réseaux de reconnaissance d'images ResNet-50 et VGG19 avec des tailles de lots de 1 à 128 par rapport à la Jetson TX2. Ces modèles classifient des patchs d'images avec une résolution de 224×224 et sont fréquemment utilisés comme épine dorsale d'encodage dans divers réseaux de détection d'objets. L'utilisation d'une taille de lot de 8 ou plus à la résolution la plus basse peut être utilisée pour approcher les performances et la latence d'une taille de lot de 1 à des résolutions plus élevées. Les plateformes robotiques et les machines autonomes intègrent souvent plusieurs caméras et capteurs qui peuvent être traités par lots pour améliorer les performances, en plus de la détection des régions d'intérêt (ROI) suivie d'une classification plus poussée des ROI par lots. La figure ci-dessous comprend également des estimations des performances futures de la Jetson AGX Xavier, intégrant des améliorations logicielles telles que la prise en charge de l'INT8 pour le DLA et des optimisations supplémentaires pour le GPU.
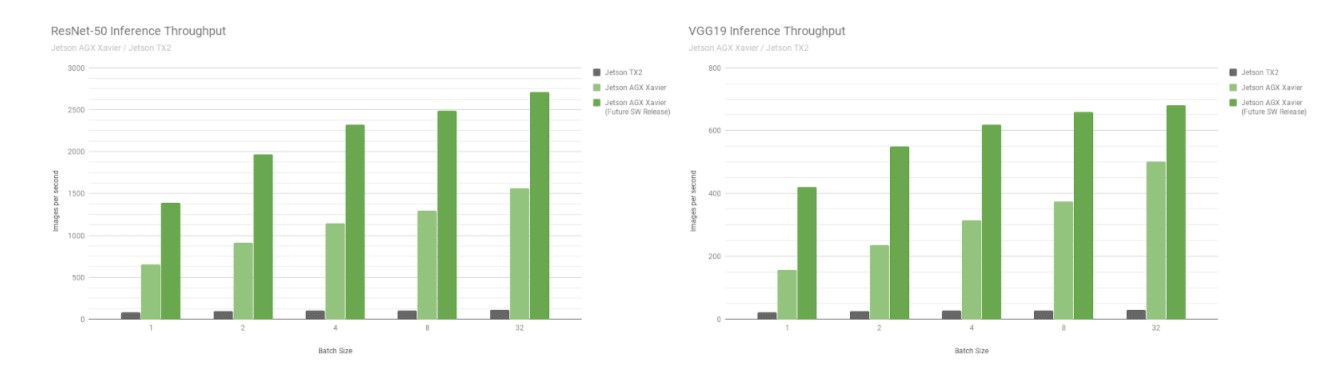 Performances estimées après la prise en charge de l'INT8 pour le DLA et les optimisations supplémentaires pour le GPU
Performances estimées après la prise en charge de l'INT8 pour le DLA et les optimisations supplémentaires pour le GPU
La Jetson AGX Xavier atteint actuellement un débit 18 fois supérieur à celui de la Jetson TX2 sur VGG19 et 14 fois supérieur sur ResNet-50, mesuré avec JetPack 4.1.1, comme le montre la figure ci-dessous. La latence de ResNet-50 est aussi faible que 1,5 ms, ou plus de 650FPS avec une taille de lot de 1. On estime que la Jetson AGX Xavier sera jusqu'à 24 fois plus rapide que la Jetson TX2 avec de futures améliorations logicielles. Notez que pour les comparaisons historiques, nous fournissons également des données pour GoogleNet et AlexNet dans les listes de performances complètes.
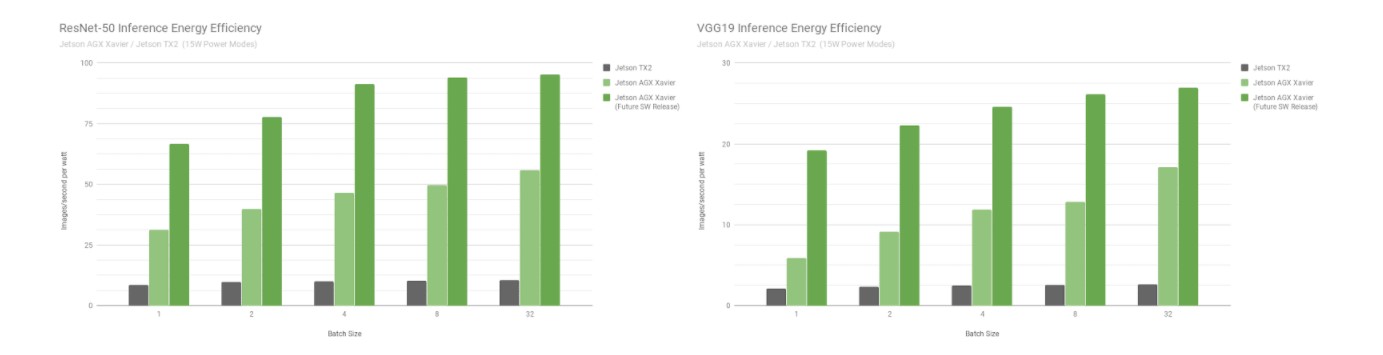 Efficacité énergétique de ResNet-50 et VGG19 pour Jetson Xavier et Jetson TX2
Efficacité énergétique de ResNet-50 et VGG19 pour Jetson Xavier et Jetson TX2
La Jetson AGX Xavier est actuellement plus de 7 fois plus efficace pour l'inférence VGG19 que la Jetson TX2 et 5 fois plus efficace avec ResNet-50, avec une augmentation de l'efficacité pouvant aller jusqu'à 10 fois si l'on prend en compte les optimisations et améliorations logicielles futures. Consultez les résultats complets des performances pour obtenir des données supplémentaires et des détails sur les benchmarks d'inférence. Nous évaluons également les performances de l'unité centrale dans la section suivante.
Complexe CPU Carmel
Le complexe CPU de la Jetson AGX Xavier, comme le montre la photo ci-dessous, se compose de quatre clusters CPU NVIDIA Carmel hétérogènes à double cœur basés sur ARMv8.2 avec une fréquence d'horloge maximale de 2,26 GHz. Chaque cœur comprend des caches L1 de 128 Ko d'instructions et de 64 Ko de données, ainsi qu'un cache L2 de 2 Mo partagé entre les deux cœurs. Les clusters de CPU partagent un cache L3 de 4 Mo.

Schéma fonctionnel du complexe CPU Jetson Xavier avec les clusters NVIDIA Carmel
Les cœurs du CPU Carmel sont dotés de l'optimisation dynamique du code de NVIDIA, d'une architecture superscalaire à 10 voies et d'une implémentation complète de l'ARMv8.2 comprenant le SIMD avancé, le VFP (Vector Floating Point) et l'ARMv8.2-FP16.
Le benchmark SPECint_rate mesure le débit du processeur pour les systèmes multicœurs. Le score de performance global fait la moyenne de plusieurs sous-tests intensifs, notamment la compression, les opérations vectorielles et graphiques, la compilation de code et l'exécution de l'IA pour des jeux tels que les échecs et le Go. La figure ci-dessous montre les résultats des tests de référence avec une augmentation de plus de 2,5 fois des performances du processeur entre les générations.
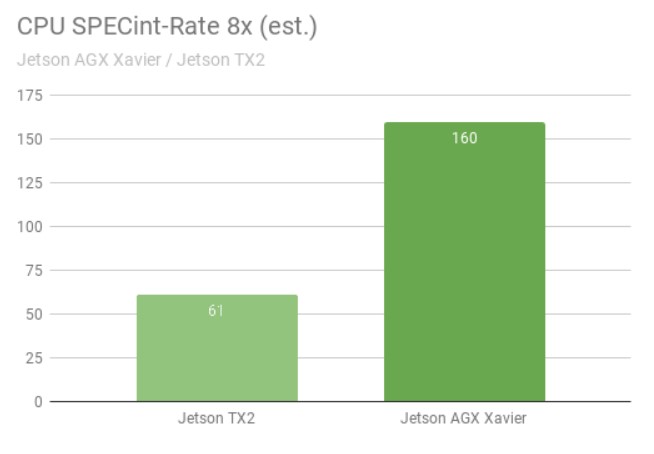 Performances de l'unité centrale de la Jetson AGX Xavier cs. Jetson TX2 dans le benchmark SPECint
Performances de l'unité centrale de la Jetson AGX Xavier cs. Jetson TX2 dans le benchmark SPECint
Huit copies simultanées des tests SPECint_rate ont été exécutées, les processeurs étant chargés au maximum. La Jetson AGX Xavier possède naturellement huit cœurs de CPU ; l'architecture de la Jetson TX2 utilise quatre cœurs Arm Cortex-A57 et deux cœurs NVIDIA Denver D15. L'exécution de deux copies par cœur Denver permet d'obtenir de meilleures performances.
Accélérateur de vision
La Jetson AGX Xavier est dotée de deux moteurs Vision Accelerator, comme le montre la figure ci-dessous. Chacun comprend un double processeur vectoriel VLIW (Very Long Instruction Word) à 7 voies qui décharge les algorithmes de vision artificielle tels que la détection et la correspondance des caractéristiques, le flux optique, la correspondance des blocs de disparité stéréo et le traitement des nuages de points avec une faible latence et une faible consommation d'énergie. Les filtres d'imagerie tels que les convolutions, les opérateurs morphologiques, l'histogramme, la conversion de l'espace colorimétrique et le gauchissement sont également idéaux pour l'accélération.
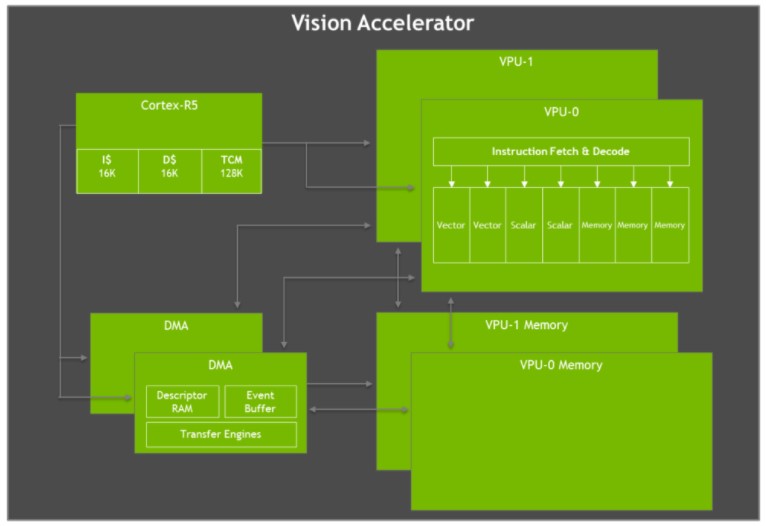 Schéma fonctionnel de l'architecture de l'accélérateur de vision Jetson AGX Xavier VLIW
Schéma fonctionnel de l'architecture de l'accélérateur de vision Jetson AGX Xavier VLIW
Chaque accélérateur de vision comprend un cœur Cortex-R5 pour la commande et le contrôle, deux unités de traitement vectoriel (chacune avec 192 Ko de mémoire vectorielle sur la puce) et deux unités DMA pour le mouvement des données. Les unités de traitement vectoriel à 7 voies contiennent des emplacements pour deux opérations vectorielles, deux opérations scalaires et trois opérations de mémoire par instruction. La version logicielle Early Access ne prend pas en charge l'accélérateur de vision, mais cette fonction sera activée dans une prochaine version de JetPack.
Kit de développement NVIDIA Jetson AGX Xavier
Le kit de développement Jetson AGX Xavier contient tout ce dont les développeurs ont besoin pour être rapidement opérationnels. Le kit comprend le module de calcul Jetson AGX Xavier, la carte de référence open-source, l'alimentation et le SDK JetPack, ce qui permet aux utilisateurs de commencer rapidement à développer des applications.

Kit de développement Jetson AGX Xavier, comprenant le module Jetson AGX Xavier et la carte porteuse de référence.
Avec 105 mm2, le kit de développement Jetson AGX Xavier est nettement plus petit que les kits de développement Jetson TX1 et TX2, tout en améliorant les E/S disponibles. Les capacités d'E/S comprennent deux ports USB3.1 (prenant en charge DisplayPort et Power Delivery), un port hybride eSATAp + USB3.0, un emplacement PCIe x16 (x8 électrique), des sites pour les mezzanines M.2 Key-M NVMe et M.2 Key-E WLAN, Gigabit Ethernet, HDMI 2.0, et un connecteur MIPI CSI pour 8 caméras. Voir le tableau 3 ci-dessous pour une liste complète des E/S disponibles sur la carte porteuse de référence du kit de développement
|
E/S du kit de développement |
Interface du module Jetson AGX Xavier |
|
PCIe x16 |
PCIe x8 Gen 4/ SLVS x8 |
|
RJ45 |
Gigabit Ethernet |
|
USB-C |
2x USB3.1 (DisplayPort en option) (Power Delivery en option) |
|
Connecteur de caméra |
16x MIPI CSI-2 lanes, jusqu'à 6 flux de capteurs actifs |
|
Clé M.2 M |
NVMe x4 |
|
Clé M.2 E |
PCIe x1 (pour Wi-Fi/ LTE/ 5G) + USB2 + UART + I2S/PCM |
|
en-tête à 40 broches |
UART + SPI + CAN + I2C + I2S + DMIC + GPIOs |
|
En-tête HD Audio |
Audio haute définition |
|
eSATAp + USB 3.0 |
SATA via pont PCIe x1 (alimentation + données pour SATA 2,5") + USB 3.0 |
|
HDMI Type A |
HDMI 2.0, Edp 1.2A, DP 1.4 |
|
Prise pour carte Usd/UFS |
SD/UFS |
Ports E/S disponibles sur le kit de développement Jetson AGX Xavier
Analyse vidéo intelligente (IVA)
L'IA et l'apprentissage profond permettent d'utiliser efficacement de grandes quantités de données pour rendre les villes plus sûres et plus pratiques, avec des applications telles que la gestion du trafic, les parkings intelligents et la rationalisation des caisses dans les magasins de détail. NVIDIA Jetson et NVIDIA DeepStream SDK permettent aux caméras intelligentes distribuées d'effectuer une analyse vidéo intelligente à la périphérie en temps réel, réduisant les charges massives de bande passante placées sur l'infrastructure de transmission et améliorant la sécurité ainsi que l'anonymat.
La Jetson TX2 peut traiter deux flux HD simultanément avec détection et suivi d'objets. Comme le montre la vidéo ci-dessus, la Jetson AGX Xavier est capable de traiter simultanément 30 flux vidéo HD indépendants à 1080p30, soit une amélioration de 15 fois. La Jetson AGX Xavier offre un débit total de plus de 1850MP/s, ce qui lui permet de décoder, de prétraiter, d'effectuer l'inférence avec la détection basée sur ResNet et de visualiser chaque image en un peu plus d'une milliseconde. Les capacités de Jetson AGX Xavier augmentent considérablement les niveaux de performance et d'évolutivité de l'analyse vidéo en périphérie.
Une nouvelle ère d'autonomie
Jetson AGX Xavier offre des niveaux de performance sans précédent à bord des robots et des machines intelligentes. Ces systèmes nécessitent des capacités de calcul exigeantes pour la perception, la navigation et la manipulation pilotées par l'IA afin d'assurer un fonctionnement autonome robuste. Les applications comprennent la fabrication, l'inspection industrielle, l'agriculture de précision et les services à domicile. Les robots de livraison autonomes qui livrent des colis aux consommateurs finaux et soutiennent la logistique dans les entrepôts, les magasins et les usines représentent une classe d'application.
Un pipeline de traitement typique pour la livraison et la logistique entièrement autonomes nécessite plusieurs étapes de tâches de vision et de perception, comme le montre la figure ci-dessous. Les robots de livraison mobiles sont souvent équipés de plusieurs caméras HD périphériques qui fournissent une connaissance de la situation à 360°, en plus du LIDAR et d'autres capteurs de distance qui sont fusionnés dans le logiciel avec les capteurs inertiels. Une caméra de conduite stéréo orientée vers l'avant est souvent utilisée, ce qui nécessite un prétraitement et une cartographie de profondeur stéréo. NVIDIA a créé des modèles DNN stéréo avec une précision améliorée par rapport aux méthodes traditionnelles de correspondance de blocs pour prendre en charge cette tâche.
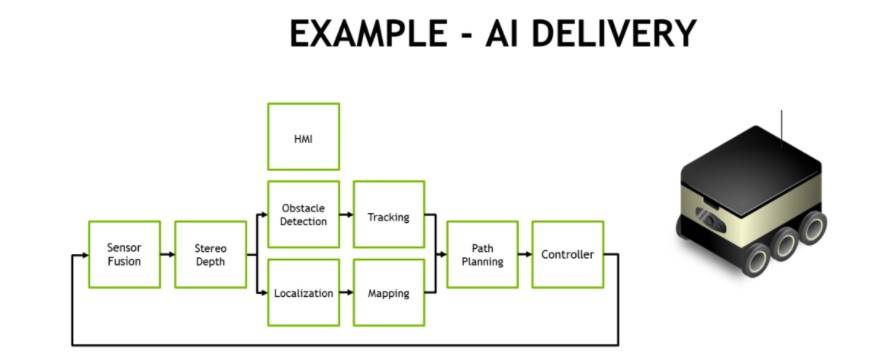 Exemple de pipeline de traitement de l'IA d'un robot autonome de livraison et de logistique
Exemple de pipeline de traitement de l'IA d'un robot autonome de livraison et de logistique
Les modèles de détection d'objets tels que SSD ou Faster-RCNN et le suivi basé sur les caractéristiques permettent généralement d'éviter les obstacles tels que les piétons, les véhicules et les points de repère. Dans le cas des robots d'entrepôt et de magasin, ces modèles de détection d'objets localisent les éléments d'intérêt tels que les produits, les étagères et les codes-barres. La reconnaissance faciale, l'estimation de la pose et la reconnaissance automatique de la parole (ASR) facilitent l'interaction homme-machine (HMI) afin que le robot puisse coordonner et communiquer efficacement avec les humains.
La localisation et la cartographie simultanées (SLAM) à haute cadence sont essentielles pour que le robot conserve une position précise en 3D. Le GPS seul manque de précision pour un positionnement sub-métrique et n'est pas disponible à l'intérieur. Le SLAM effectue l'enregistrement et l'alignement des dernières données du capteur avec les données précédentes que le système a accumulées dans son nuage de points. Les données de capteurs souvent bruitées nécessitent un filtrage important pour une localisation correcte, en particulier pour les plates-formes en mouvement.
L'étape de planification de la trajectoire utilise souvent des réseaux de segmentation sémantique tels que ResNet-18 FCN, SegNet ou DeepLab pour effectuer la détection de l'espace libre, indiquant au robot où conduire sans obstacle. Il existe fréquemment dans le monde réel trop de types d'obstacles génériques à détecter et à suivre individuellement, c'est pourquoi une approche basée sur la segmentation étiquette chaque pixel ou voxel avec sa classification. Avec les étapes précédentes du pipeline, cette classification informe le planificateur et la boucle de contrôle des itinéraires sûrs qu'il peut emprunter.
Les performances et l'efficacité de Jetson AGX Xavier permettent de traiter à bord tous les composants nécessaires en temps réel pour que ces robots fonctionnent en toute sécurité et en toute autonomie, y compris les algorithmes de vision haute performance pour la perception, la navigation et la manipulation en temps réel. Les modules autonomes Jetson AGX Xavier étant désormais livrés en production, les développeurs peuvent déployer ces solutions d'IA pour la prochaine génération de machines autonomes.
Assured Systems et NVIDIA Jetson AGX Xavier
Sur Assured Systems, nous fournissons une large gamme de produits Jetson, y compris des produits basés sur la Jetson AGX Xavier qui apportent des niveaux de calcul révolutionnaires à la robotique et aux appareils périphériques, en apportant les performances d'une station de travail haut de gamme à une plate-forme intégrée optimisée en termes de taille, de poids et de puissance.
Contactez-nous dès maintenant pour toute demande de renseignements concernant votre projet.










