In diesem artikel:
NVIDIA Jetson AGX Xavier für eine neue Ära der KI in der Robotik
Der NVIDIA Jetson AGX Xavier liefert 32 TeraOps für eine neue Ära der KI in der Robotik und sorgt damit für bahnbrechende Rechenleistung.
Die weltweit ultimative Embedded-Lösung für KI-Entwickler, Jetson AGX Xavier, ist jetzt als eigenständiges Produktionsmodul von NVIDIA erhältlich. Als Mitglied von NVIDIAs AGX-Systemen für autonome Maschinen ist Jetson AGX Xavier ideal für den Einsatz von fortschrittlicher KI und Computer Vision an der Grenze, um Roboterplattformen im Feld mit einer Leistung auf Workstation-Niveau und der Fähigkeit, völlig autonom zu operieren, ohne auf menschliche Eingriffe und Cloud-Konnektivität angewiesen zu sein, zu ermöglichen. Intelligente Maschinen, die von Jetson AGX Xavier angetrieben werden, haben die Freiheit, in ihren Umgebungen zu interagieren und sicher zu navigieren, unbelastet von komplexem Terrain und dynamischen Hindernissen, und erfüllen reale Aufgaben mit völliger Autonomie. Dazu gehören die Auslieferung von Paketen und industrielle Inspektionen, die ein hohes Maß an Echtzeit-Wahrnehmung und Schlussfolgerungen erfordern. Als weltweit erster Computer, der speziell für Robotik und Edge Computing entwickelt wurde, ist der Jetson AGX Xavier in der Lage, visuelle Odometrie, Sensorfusion, Lokalisierung und Kartierung, Hinderniserkennung und Pfadplanungsalgorithmen zu bewältigen, die für die Roboter der nächsten Generation entscheidend sind. Das Foto unten zeigt die Produktionsrechenmodule, die jetzt weltweit verfügbar sind. Entwickler können jetzt damit beginnen, neue autonome Maschinen in großen Stückzahlen einzusetzen.
 Jetson AGX Xavier eingebettetes Rechenmodul mit Thermotransferplatte (TTP), 100x87mm
Jetson AGX Xavier eingebettetes Rechenmodul mit Thermotransferplatte (TTP), 100x87mm
Die neueste Generation von NVIDIAs branchenführenden Embedded-Linux-Hochleistungscomputern der Jetson AGX-Familie, Jetson AGX Xavier, bietet GPU-Workstation-Performance mit beispiellosen 32 TeraOPS (TOPS) Spitzenleistung und 750 Gbps Hochgeschwindigkeits-I/O in einem kompakten 100x87mm-Formfaktor. Benutzer können die Betriebsmodi 10W, 15W und 30W je nach Bedarf für ihre Anwendungen konfigurieren. Jetson AGX Xavier setzt neue Maßstäbe bei der Rechendichte, der Energieeffizienz und den KI-Funktionen für den Einsatz im Edge-Bereich und ermöglicht intelligente Maschinen der nächsten Generation mit durchgängig autonomen Fähigkeiten.
Jetson treibt die KI hinter vielen der fortschrittlichsten Roboter und autonomen Maschinen der Welt an, indem es Deep Learning und Computer Vision einsetzt und sich dabei auf Leistung, Effizienz und Programmierbarkeit konzentriert. Der Jetson AGX Xavier, der in der Abbildung unten dargestellt ist, besteht aus über 9 Milliarden Transistoren und basiert auf dem komplexesten System-on-Chip (SoC), das jemals entwickelt wurde. Die Plattform umfasst eine integrierte 512-Kern-NVIDIA-Volta-GPU mit 64 Tensor-Cores, eine 8-Kern-NVIDIA-Carmel-ARMv8.2-64-Bit-CPU, 16 GB 256-Bit-LPDDR4x, zwei NVIDIA-Deep-Learning-Accelerator-Engines (DLA), eine NVIDIA-Vision-Accelerator-Engine, HD-Videocodecs, 128 Gbit/s für dedizierten Kamera-Ingest und 16 Lanes für PCIe-Gen-4-Erweiterung. Die Speicherbandbreite über die 256-Bit-Schnittstelle beträgt 137 GB/s, während die DLA-Engines das Inferencing von Deep Neural Networks (DNNs) auslagern.NVIDIAs JetPack SDK 4.1.1 für den Jetson AGX Xavier umfasst CUDA 10.0, cuDNN 7.3 und TensorRT 5.0 und bietet damit den kompletten AI-Software-Stack.
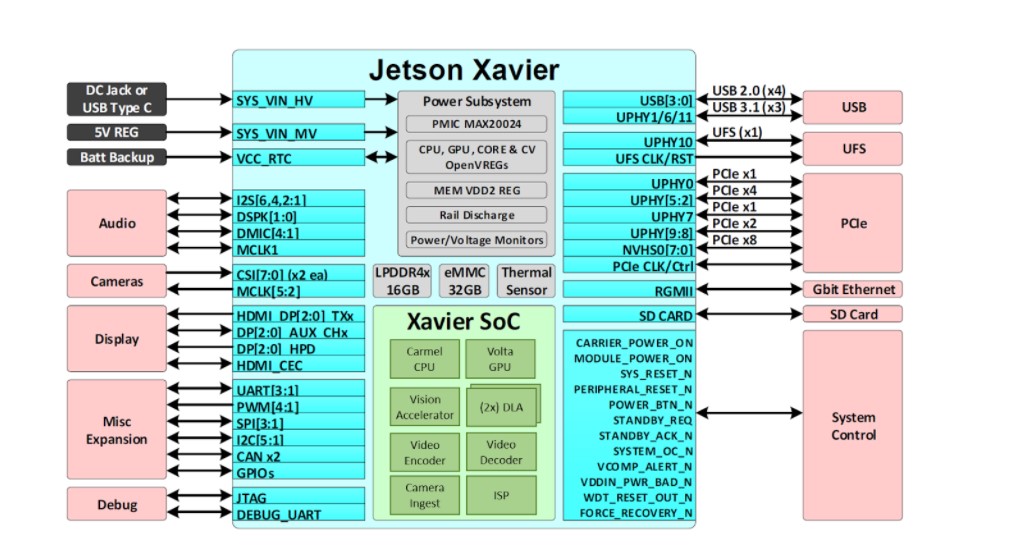 Jetson AGX Xavier bietet ein umfangreiches Angebot an Hochgeschwindigkeits-I/O
Jetson AGX Xavier bietet ein umfangreiches Angebot an Hochgeschwindigkeits-I/O
Dies ermöglicht es Entwicklern, beschleunigte KI in Anwendungen wie Robotik, intelligente Videoanalyse, medizinische Instrumente, eingebettete IoT-Edge-Geräte und mehr einzusetzen. Wie seine Vorgänger Jetson TX1 und TX2 verwendet Jetson AGX Xavier ein System-on-Module (SoM) Paradigma. Die gesamte Verarbeitung befindet sich auf dem Rechenmodul, während die Hochgeschwindigkeits-E/A auf einem Breakout-Carrier oder einem Gehäuse untergebracht sind, das über einen High-Density-Board-to-Board-Anschluss bereitgestellt wird. Die Kapselung der Funktionalität auf dem Modul macht es Entwicklern leicht, Jetson Xavier in ihre eigenen Designs zu integrieren. NVIDIA hat eine umfassende Dokumentation und Referenzdesign-Dateien zum Herunterladen für Embedded-Designer veröffentlicht, die ihre eigenen Geräte und Plattformen mit Jetson AGX Xavier entwickeln.
Im Jetson AGX Xavier Modul-Datenblatt und im Jetson AGX Xavier OEM-Produktdesign-Leitfaden finden Sie alle in der unten stehenden Tabelle aufgeführten Produktmerkmale sowie die elektromechanischen Spezifikationen, die Pinbelegung des Moduls, die Stromversorgungsreihenfolge und die Richtlinien für das Signalrouting.
|
NVIDIA Jetson AGX Xavier Modul |
|
|
CPU |
8-Kern NVIDIA Carmel 64-Bit ARMv8.2 @ 2265MHz |
|
GPU |
512-Kern NVIDIA Volta @ 1377MHz mit 64 TensorCores |
|
DL |
Zwei NVIDIA Deep Learning-Beschleuniger (DLAs) |
|
Arbeitsspeicher und Speicher |
16GB 256-bit LPDDR4x @ 2133MHz | 137GB/s 32 GB eMMC 5.1 |
|
Vision |
(2x) 7-Wege-VLIW-Vision-Beschleuniger |
|
Encoder* |
(4x) 4Kp60 | (8x) 4Kp30 | (16x) 1080p60 | (32x) 1080p30Maximaler Durchsatz bis zu (2x) 1000MP/s - H.265 Main |
|
Decoder* |
(2x) 8Kp30 | (6x) 4Kp60 | (12x) 4Kp30 | (26x) 1080p60 | (52x) 1080p30Maximaler Durchsatz bis zu (2x) 1500MP/s - H.265 Main |
|
Kamera†. |
(16x) MIPI CSI-2 Lanes, (8x) SLVS-EC Lanes; bis zu 6 aktive Sensorströme und 36 virtuelle Kanäle |
|
Anzeige |
(3x) eDP 1.4 / DP 1.2 / HDMI 2.0 @ 4Kp60 |
|
Ethernet |
10/100/1000 BASE-T Ethernet + MAC + RGMII Schnittstelle |
|
USB |
(3x) USB 3.1 + (4x) USB 2.0 |
|
PCIe†† |
(5x) PCIe Gen 4-Controller | 1×8, 1×4, 1×2, 2×1 |
|
CAN |
Zweifache CAN-Bus-Steuerung |
|
Diverse E/As |
UART, SPI, I2C, I2S, GPIOs |
|
Sockel |
699-poliger Board-to-Board-Anschluss, 100x87mm mit 16mm Z-Höhe |
|
Thermik‡ |
-25°C bis 80°C |
|
Leistung |
10W / 15W / 30W Profile, 9.0V-20VDC Eingang |
|
*Maximale Anzahl von gleichzeitigen Streams bis zum Gesamtdurchsatz. Unterstützte Video-Codecs: H.265, H.264, VP9Spezifische Codec- und Profilspezifikationen finden Sie im Datenblatt des Jetson AGX Xavier Moduls unter §1.6.1 und §1.6.2.+MIPI CSI-2, bis zu 40 Gbps in D-PHY V1.2 oder 109 Gbps in CPHY v1.1SLVS-EC, bis zu 18,4 Gbit/s++(3x) Root Port + Endpoint-Controller und (2x) Root Port-Controller+Betriebstemperaturbereich, Thermal Transfer Plate (TTP) maximale Sperrschichttemperatur. |
|
Jetson AGX Xavier verfügt über mehr als 750 Gbit/s an Hochgeschwindigkeits-E/A und bietet damit eine außerordentlich hohe Bandbreite für das Streaming von Sensoren und Hochgeschwindigkeits-Peripheriegeräten. Es ist eines der ersten Embedded-Geräte, das PCIe Gen 4 unterstützt und 16 Lanes über fünf PCIe Gen 4-Controller bereitstellt, von denen drei im Root-Port- oder Endpoint-Modus arbeiten können. an die 16 MIPI CSI-2-Lanes können vier 4-Lane-Kameras, sechs 2-Lane-Kameras, sechs 1-Lane-Kameras oder eine Kombination dieser Konfigurationen mit bis zu sechs Kameras angeschlossen werden, wobei 36 virtuelle Kanäle den gleichzeitigen Anschluss weiterer Kameras durch Stream-Aggregation ermöglichen. Weitere Hochgeschwindigkeits-E/A umfassen drei USB 3.1-Ports, SLVS-EC, UFS und RGMII für Gigabit Ethernet. Entwickler haben jetzt Zugang zu NVIDIAs JetPack 4.1.1 Developer Preview Software für Jetson AGX Xavier, die in der Tabelle unten aufgeführt ist. Die Developer Preview enthält Linux For Tegra (L4T) R31.1 Board Support Package (BSP) mit Unterstützung für Linux Kernel 4.9 und Ubuntu 18.04 auf dem Target. Auf der Host-PC-Seite unterstützt JetPack 4.1.1 Ubuntu 16.04 und Ubuntu 18.04.
|
NVIDIA JetPack 4.1.1 Developer Preview Release |
|
|
L4T R31.0.1 (Linux K4.9) |
Ubuntu 18.04 LTS aarch64 |
|
CUDA Werkzeugsatz 10.0 |
cuDNN 7.3 |
|
TensorRT 5.0 GA |
GStreamer 1.14.1 |
|
VisionWorks 1.6 |
OpenCV 3.3.1 |
|
OpenGL 4.6 / GLES 3.2 |
Vulkan 1.1 |
|
NVIDIA Nsight Systeme 2018.1 |
NVIDIA Nsight Grafik 2018.6 |
|
Multimedia-API R31.1 |
Argus 0.97 Kamera-API |
Softwarekomponenten in JetPack 4.1.1 Developer Preview und L4T BSP für Jetson AGX Xavier
Mit der JetPack 4.1.1 Developer Preview können Entwickler sofort mit der Entwicklung von Prototypen für Produkte und Anwendungen mit Jetson AGX Xavier beginnen, um sich auf den Einsatz in der Produktion vorzubereiten. NVIDIA wird JetPack weiterhin mit zusätzlichen Funktionen und Leistungsoptimierungen verbessern. Bitte lesen Sie die Release Notes für die Highlights und den Softwarestand dieser Version.
Volta-GPU
Der in Jetson AGX Xavier integrierte Volta-Grafikprozessor (siehe Abbildung 3) bietet 512 CUDA-Kerne und 64 Tensor-Cores für bis zu 11 TFLOPS FP16 oder 22 TOPS INT8-Rechenleistung bei einer maximalen Taktfrequenz von 1,37 GHz. Sie unterstützt CUDA 10 mit einer Rechenleistung von sm_72. Die GPU umfasst acht Volta Streaming Multiprozessoren (SMs) mit 64 CUDA-Kernen und 8 Tensor-Kernen pro Volta SM. Jeder Volta SM verfügt über einen 128 KB großen L1-Cache, der 8-mal größer ist als bei früheren Generationen. Die SMs teilen sich einen 512 KB großen L2-Cache und bieten einen 4x schnelleren Zugriff als frühere Generationen.
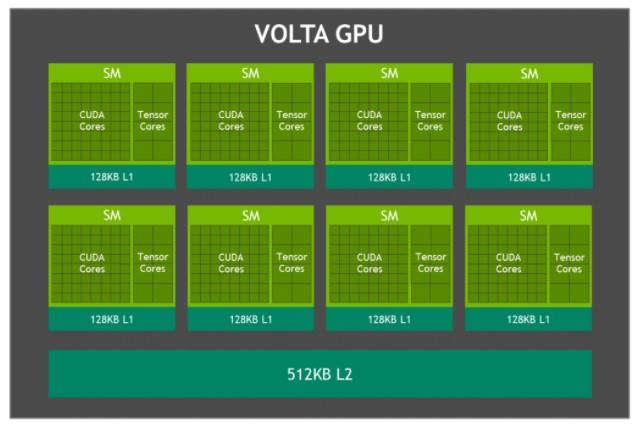 Blockdiagramm der Jetson AGX Xavier Volta GPU
Blockdiagramm der Jetson AGX Xavier Volta GPU
Jeder SM besteht aus vier separaten Verarbeitungsblöcken, die als SMPs (Streaming Multiprocessor Partitions) bezeichnet werden und jeweils einen eigenen L0-Befehlscache, einen Warp-Scheduler, eine Dispatch-Einheit und eine Registerdatei sowie CUDA-Kerne und Tensor Cores enthalten. Mit doppelt so vielen SMPs pro SM wie bei Pascal bietet der Volta SM eine verbesserte Gleichzeitigkeit und unterstützt mehr Threads, Warps und Thread-Blöcke im Flug.
Tensor-Kerne
NVIDIA Tensor Cores sind programmierbare fusionierte Matrix-Multiplikations- und Akkumulationseinheiten, die gleichzeitig mit CUDA Cores ausgeführt werden. Tensor Cores implementieren die neuen Fließkomma-HMMA- (Half-Precision Matrix Multiply and Accumulate) und IMMA- (Integer Matrix Multiply and Accumulate) Befehle zur Beschleunigung von dichten linearen Algebra-Berechnungen, Signalverarbeitung und Deep Learning Inferenz.
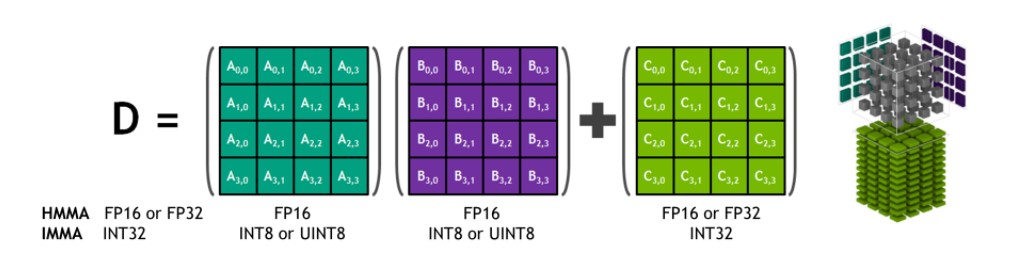
Tensor Core HMMA/IMMA 4x4x4-Matrix-Multiplikation und -Akkumulation
Die Matrixmultiplikationseingänge A und B sind FP16-Matrizen für HMMA-Anweisungen, während die Akkumulationsmatrizen C und D FP16- oder FP32-Matrizen sein können. Bei IMMA ist der Multiplikationseingang A eine vorzeichenbehaftete oder vorzeichenlose INT8- oder INT16-Matrix, B ist eine vorzeichenbehaftete oder vorzeichenlose INT8-Matrix, und die Akkumulationsmatrizen C und D sind vorzeichenbehaftete INT32-Matrizen. Daher ist der Bereich der Genauigkeit und der Berechnung ausreichend, um Überlauf- und Unterlaufbedingungen während der internen Akkumulation zu vermeiden.
NVIDIA-Bibliotheken wie cuBLAS, cuDNN und TensorRT wurden aktualisiert, um HMMA und IMMA intern zu nutzen, so dass Programmierer die Vorteile der Leistungssteigerung von Tensor Cores einfach nutzen können. Benutzer können auch direkt auf Tensor-Core-Operationen auf Warp-Ebene über eine neue API zugreifen, die im wmma-Namensraum und im mma.h-Header von CUDA 10 enthalten ist. Die Schnittstelle auf Warp-Ebene bildet Matrizen der Größen 16×16, 32×8 und 8×32 über alle 32 Threads pro Warp ab.
Deep Learning-Beschleuniger
Jetson AGX Xavier verfügt über zwei NVIDIA Deep Learning Accelerator (DLA)-Engines (siehe Abbildung unten), die das Inferencing von Convolutional Neural Networks (CNNs) mit fester Funktion entlasten. Diese Engines verbessern die Energieeffizienz und setzen den Grafikprozessor für die Ausführung komplexerer Netzwerke und dynamischer, vom Benutzer implementierter Aufgaben frei. Die NVIDIA DLA-Hardwarearchitektur ist quelloffen und unter NVDLA.org verfügbar. Jede DLA hat eine Leistung von bis zu 5 TOPS INT8 oder 2,5 TFLOPS FP16 bei einer Leistungsaufnahme von nur 0,5-1,5 W. Die DLAs unterstützen die Beschleunigung von CNN-Schichten wie Faltung, Entfaltung, Aktivierungsfunktionen, Min/Max/Mittelwert-Pooling, lokale Antwortnormalisierung und vollständig verbundene Schichten.
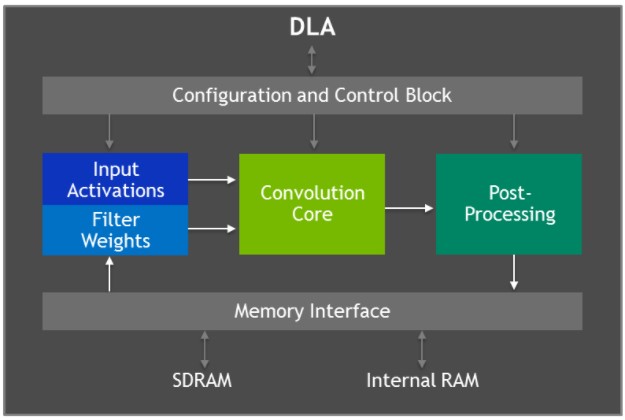 Blockdiagramm der Architektur des Deep Learning Accelerators (DLA)
Blockdiagramm der Architektur des Deep Learning Accelerators (DLA)
Die DLA-Hardware besteht aus den folgenden Komponenten:
- Convolution Core - optimierte Hochleistungs-Faltungs-Engine.
- Single Data Processor - Single-Point-Lookup-Engine für Aktivierungsfunktionen.
- Planar Data Processor - Planar Averaging Engine für Pooling.
- Kanaldatenprozessor - Mehrkanal-Mittelungs-Engine für erweiterte Normalisierungsfunktionen.
- Dedizierte Speicher- und Datenumformungs-Engines - Speicher-zu-Speicher-Transformationsbeschleunigung für Tensorumformung und Kopieroperationen.
Entwickler programmieren DLA-Engines mit TensorRT 5.0, um Inferencing auf Netzwerken durchzuführen, einschließlich Unterstützung für AlexNet, GoogleNet und ResNet-50. Für Netzwerke, die Schichtkonfigurationen verwenden, die von DLA nicht unterstützt werden, bietet TensorRT GPU Fallback für die Schichten, die nicht auf DLAs ausgeführt werden können. Die JetPack 4.0 Developer Preview beschränkt die DLA-Präzision zunächst auf den FP16-Modus, wobei INT8-Präzision und höhere Leistung für DLA in einem zukünftigen JetPack-Release kommen werden.
TensorRT 5.0 fügt die folgenden APIs zu seiner IBuilder Schnittstelle hinzu, um die DLAs zu aktivieren:
- Set Device Type() und set Default Device Type() zur Auswahl von GPU, DLA_0 oder DLA_1 für die Ausführung einer bestimmten Schicht oder standardmäßig für alle Schichten im Netzwerk.
- Can Run On DLA(), um zu prüfen, ob eine Schicht wie konfiguriert auf DLA laufen kann.
- Get Max DLA Batch Size() zum Abrufen der maximalen Stapelgröße, die DLA unterstützen kann.
- Allow GPU Fallback(), um der GPU die Ausführung von Schichten zu ermöglichen, die von DLA nicht unterstützt werden.
Deep Learning Inferencing Benchmarks
Wir haben Deep Learning Inferencing Benchmark-Ergebnisse für Jetson AGX Xavier auf gängigen DNNs wie Varianten von ResNet, GoogleNet und VGG veröffentlicht. Wir haben diese Benchmarks für Jetson AGX Xavier unter Verwendung der JetPack 4.1.1 Developer Preview Release mit TensorRT 5.0 auf der GPU und den DLA-Engines von Jetson AGX Xavier durchgeführt. Die GPU und zwei DLAs führten die gleichen Netzwerkarchitekturen gleichzeitig in INT8- bzw. FP16-Präzision aus, wobei die Gesamtleistung für jede Konfiguration angegeben wurde. Die GPU und die DLAs können in realen Anwendungsfällen gleichzeitig verschiedene Netzwerke oder Netzwerkmodelle ausführen, die parallel oder in einer Verarbeitungspipeline einzigartige Funktionen erfüllen. Die Verwendung von INT8 gegenüber der vollen FP32-Präzision in TensorRT führt zu einem Genauigkeitsverlust von 1 % oder weniger.
Betrachten wir zunächst die Ergebnisse von ResNet-18 FCN (Fully Convolutional Network), einem Full-HD-Modell mit 2048×1024 Auflösung, das für die semantische Segmentierung verwendet wird. die Segmentierung bietet eine Klassifizierung pro Pixel für Aufgaben wie die Erkennung von Freiräumen und die Zuordnung von Belegungen und ist repräsentativ für Deep-Learning-Workloads, die von autonomen Maschinen für die Wahrnehmung, Pfadplanung und Navigation berechnet werden. Das folgende Diagramm zeigt den gemessenen Durchsatz bei der Ausführung von ResNet-18 FCN auf dem Jetson AGX Xavier im Vergleich zum Jetson TX2.
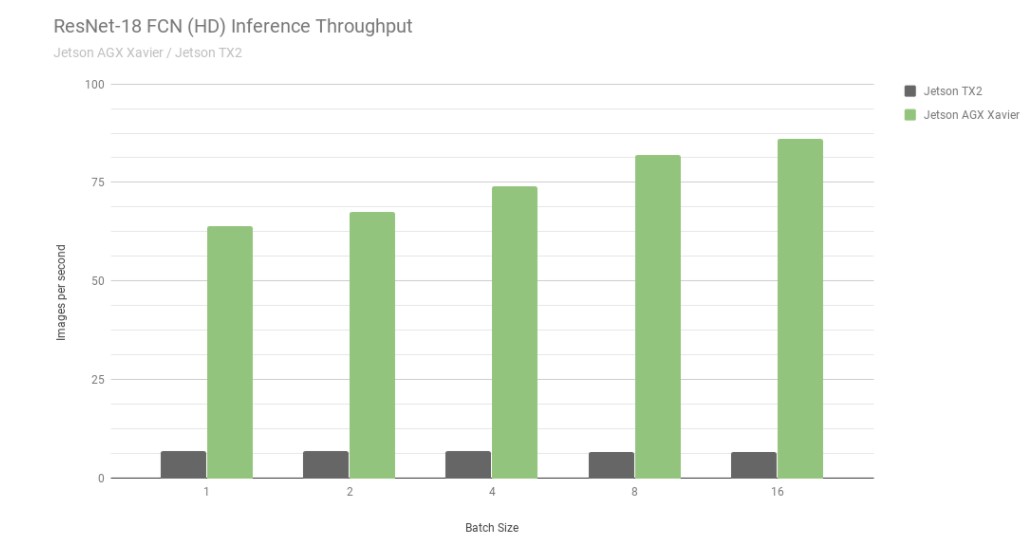 ResNet-18 FCN Inferencing-Durchsatz von Jetson AGX Xavier und Jetson TX2
ResNet-18 FCN Inferencing-Durchsatz von Jetson AGX Xavier und Jetson TX2
Der Jetson AGX Xavier erreicht derzeit die bis zu 13-fache Leistung bei der ResNet-18-FCN-Inferenz im Vergleich zum Jetson TX2. NVIDIA wird weiterhin Software-Optimierungen und Funktionserweiterungen in JetPack veröffentlichen, die die Leistung und den Stromverbrauch im Laufe der Zeit weiter verbessern werden. beachten Sie, dass die vollständige Auflistung der Benchmark-Ergebnisse die Leistung von ResNet-18 FCN für den Jetson AGX Xavier bis zu einer Stapelgröße von 32 angibt. In der untenstehenden Grafik wird jedoch nur die Leistung bis zu einer Stapelgröße von 16 dargestellt, da der Jetson TX2 in der Lage ist, ResNet-18 FCN bis zu einer Stapelgröße von 16 auszuführen.
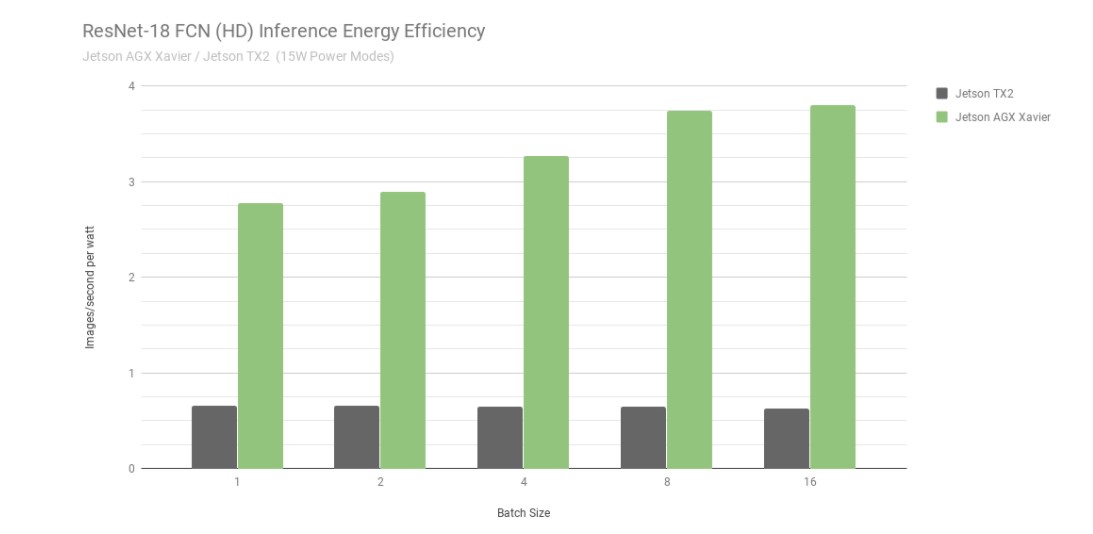
Energieeffizienz des ResNet-18 FCN-Inferencing von Jetson AGX Xavier und Jetson TX2
Betrachtet man die Energieeffizienz anhand der pro Sekunde pro Watt verarbeiteten Bilder, so ist der Jetson AGX Xavier bei ResNet-18 FCN derzeit bis zu 6-mal energieeffizienter als der Jetson TX2. Wir haben die Effizienz berechnet, indem wir die gesamte Leistungsaufnahme des Moduls mit Hilfe der integrierten INA-Spannungs- und Stromüberwachungsgeräte gemessen haben, einschließlich des Energieverbrauchs von CPU, GPU, DLAs, Speicher, sonstiger SoC-Leistung, I/O und der Effizienzverluste des Reglers auf allen Schienen. Beide Jetsons wurden im 15W-Strommodus betrieben. Jetson AGX Xavier und JetPack werden mit konfigurierbaren voreingestellten Leistungsprofilen für 10W, 15W und 30W ausgeliefert, die zur Laufzeit mit dem nvpmodel Power Management Tool umgeschaltet werden können. Benutzer können auch ihre eigenen Profile mit unterschiedlichen Taktraten und DVFS (Dynamic Voltage and Frequency Scaling)-Reglereinstellungen definieren, die darauf zugeschnitten sind, die beste Leistung für individuelle Anwendungen zu erzielen.
Als Nächstes vergleichen wir die Jetson AGX Xavier Benchmarks mit den Bilderkennungsnetzwerken ResNet-50 und VGG19 über die Losgrößen 1 bis 128 mit dem Jetson TX2. Diese Modelle klassifizieren Bildfelder mit einer Auflösung von 224×224 und werden häufig als Encoder-Backbone in verschiedenen Objekterkennungsnetzwerken verwendet. Die Verwendung einer Stapelgröße von 8 oder höher bei der niedrigeren Auflösung kann verwendet werden, um die Leistung und Latenz einer Stapelgröße von 1 bei höheren Auflösungen anzunähern. Roboterplattformen und autonome Maschinen verfügen häufig über mehrere Kameras und Sensoren, die zur Leistungssteigerung stapelweise verarbeitet werden können, und zwar zusätzlich zur Erkennung von Interessengebieten (ROIs) und der anschließenden Klassifizierung der ROIs in Stapeln. Die Abbildung unten enthält auch Schätzungen der zukünftigen Leistung für Jetson AGX Xavier, die Softwareverbesserungen wie INT8-Unterstützung für DLA und zusätzliche Optimierungen für die GPU beinhalten.
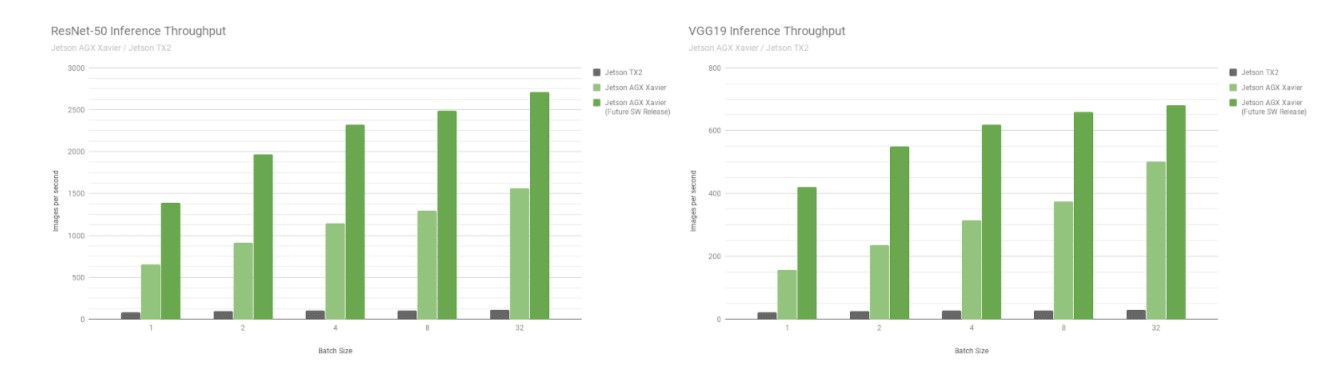 Geschätzte Leistung nach INT8-Unterstützung für DLA und zusätzlichen GPU-Optimierungen
Geschätzte Leistung nach INT8-Unterstützung für DLA und zusätzlichen GPU-Optimierungen
Jetson AGX Xavier erreicht derzeit den 18-fachen Durchsatz von Jetson TX2 auf VGG19 und den 14-fachen Durchsatz auf ResNet-50, gemessen mit JetPack 4.1.1, wie in der Abbildung unten dargestellt. Die Latenz von ResNet-50 beträgt nur 1,5 ms oder über 650 FPS bei einer Stapelgröße von 1. Es wird geschätzt, dass Jetson AGX Xavier mit zukünftigen Softwareverbesserungen bis zu 24-mal schneller als Jetson TX2 sein wird. Beachten Sie, dass wir für ältere Vergleiche auch Daten für GoogleNet und AlexNet in den vollständigen Leistungsauflistungen bereitstellen.
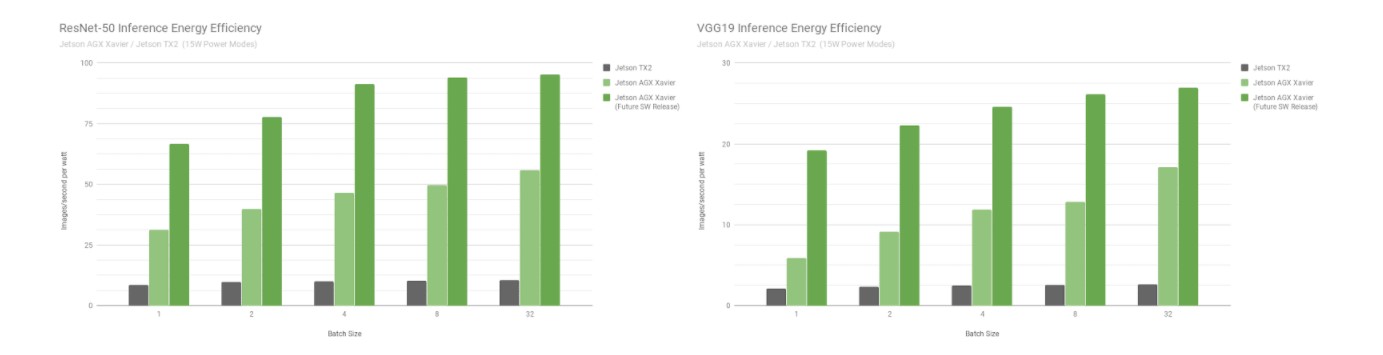 ResNet-50 und VGG19 Energieeffizienz für Jetson Xavier und Jetson TX2
ResNet-50 und VGG19 Energieeffizienz für Jetson Xavier und Jetson TX2
Der Jetson AGX Xavier ist derzeit bei der VGG19-Inferenz mehr als 7-mal effizienter als der Jetson TX2 und 5-mal effizienter mit ResNet-50, mit einer bis zu 10-fachen Steigerung der Effizienz, wenn zukünftige Software-Optimierungen und -Erweiterungen berücksichtigt werden. In den vollständigen Leistungsergebnissen finden Sie zusätzliche Daten und Details zu den Inferenz-Benchmarks. Im nächsten Abschnitt werden wir auch die CPU-Leistung bewerten.
Carmel CPU-Komplex
Der CPU-Komplex des Jetson AGX Xavier besteht aus vier heterogenen Dual-Core NVIDIA Carmel CPU-Clustern auf Basis von ARMv8.2 mit einer maximalen Taktfrequenz von 2,26 GHz. Jeder Kern verfügt über einen 128 KB großen Befehls- und einen 64 KB großen Daten-L1-Cache sowie einen 2 MB großen L2-Cache, den sich die beiden Kerne teilen. Die CPU-Cluster teilen sich einen 4 MB großen L3-Cache.

Blockdiagramm des Jetson Xavier CPU-Komplexes mit NVIDIA Carmel-Clustern
Die Carmel-CPU-Kerne verfügen über NVIDIAs Dynamic Code Optimization, eine 10-Wege-Superskalararchitektur und eine vollständige Implementierung von ARMv8.2 einschließlich Advanced SIMD, VFP (Vector Floating Point) und ARMv8.2-FP16.
Der SPECint_rate-Benchmark misst den CPU-Durchsatz für Multi-Core-Systeme. Die Gesamtleistung ergibt sich aus dem Durchschnitt mehrerer intensiver Untertests, darunter Komprimierung, Vektor- und Graphoperationen, Codekompilierung und die Ausführung von KI für Spiele wie Schach und Go. Die Abbildung unten zeigt Benchmark-Ergebnisse mit einer mehr als 2,5-fachen Steigerung der CPU-Leistung zwischen den Generationen.
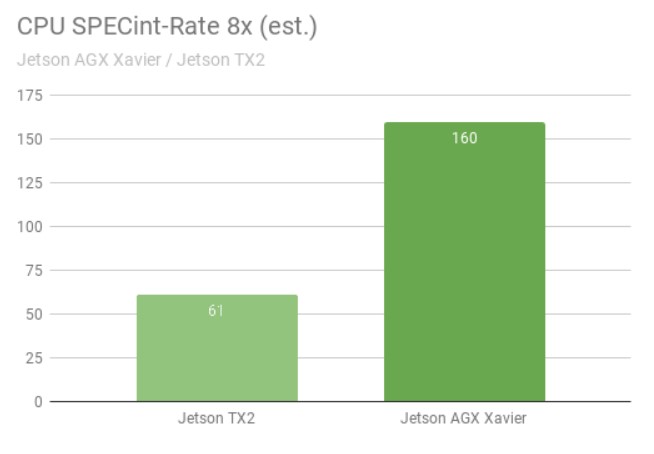 CPU-Leistung des Jetson AGX Xavier cs. Jetson TX2 im SPECint-Benchmark
CPU-Leistung des Jetson AGX Xavier cs. Jetson TX2 im SPECint-Benchmark
Die SPECint_rate-Tests wurden mit acht gleichzeitigen Kopien durchgeführt, wobei die CPUs voll ausgelastet waren. Der Jetson AGX Xavier hat natürlich acht CPU-Kerne; die Architektur des Jetson TX2 verwendet vier Arm Cortex-A57-Kerne und zwei NVIDIA Denver D15-Kerne. Die Ausführung von zwei Kopien pro Denver-Kern führt zu einer höheren Leistung.
Vision-Beschleuniger
Der Jetson AGX Xavier verfügt über zwei Vision Accelerator Engines, die in der Abbildung unten dargestellt sind. Jeder enthält einen dualen 7-Wege-VLIW-Vektorprozessor (Very Long Instruction Word), der Bildverarbeitungsalgorithmen wie Feature Detection & Matching, Optical Flow, Stereo Disparity Block Matching und Punktwolkenverarbeitung mit geringer Latenz und niedrigem Stromverbrauch auslagert. Bildverarbeitungsfilter wie Faltungen, morphologische Operatoren, Histogramming, Farbraumkonvertierung und Warping sind ebenfalls ideal für die Beschleunigung.
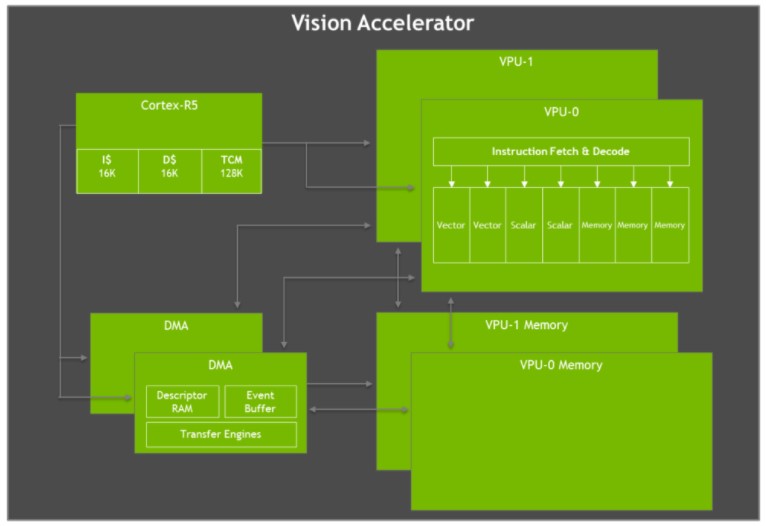 Blockdiagramm der Jetson AGX Xavier VLIW Vision Accelerator Architektur
Blockdiagramm der Jetson AGX Xavier VLIW Vision Accelerator Architektur
Jeder Vision Accelerator enthält einen Cortex-R5-Kern für die Steuerung, zwei Vektorverarbeitungseinheiten (jeweils mit 192 KB On-Chip-Vektorspeicher) und zwei DMA-Einheiten für die Datenübertragung. Die 7-Wege-Vektorverarbeitungseinheiten enthalten Steckplätze für zwei Vektor-, zwei Skalar- und drei Speicheroperationen pro Befehl. Die Early-Access-Softwareversion bietet keine Unterstützung für den Vision Accelerator, wird aber in einer zukünftigen Version von JetPack aktiviert werden.
NVIDIA Jetson AGX Xavier Entwickler-Kit
Das Jetson AGX Xavier Developer Kit enthält alles, was Entwickler benötigen, um schnell mit der Entwicklung beginnen zu können. Das Kit enthält das Jetson AGX Xavier Rechenmodul, ein Open-Source Referenz-Trägerboard, ein Netzteil und das JetPack SDK, so dass Benutzer schnell mit der Entwicklung von Anwendungen beginnen können.

Jetson AGX Xavier Developer Kit, einschließlich Jetson AGX Xavier Modul und Referenz-Trägerkarte.
Mit 105 mm2 ist das Jetson AGX Xavier Developer Kit deutlich kleiner als die Jetson TX1 und TX2 Developer Kits und bietet gleichzeitig mehr I/O-Funktionen. Zu den E/A-Funktionen gehören zwei USB3.1-Anschlüsse (mit Unterstützung für DisplayPort und Power Delivery), ein hybrider eSATAp- und USB3.0-Anschluss, ein PCIe-x16-Steckplatz (x8 elektrisch), Steckplätze für M.2 Key-M NVMe- und M.2 Key-E WLAN-Mezzanine, Gigabit-Ethernet, HDMI 2.0 und ein MIPI CSI-Anschluss für 8 Kameras. Siehe Tabelle 3 unten für eine vollständige Liste der E/As, die über das Entwickler-Kit-Referenzträgerboard verfügbar sind
|
Entwickler-Kit E/As |
Jetson AGX Xavier Modul Schnittstelle |
|
PCIe x16 |
PCIe x8 Gen 4/ SLVS x8 |
|
RJ45 |
Gigabit-Ethernet |
|
USB-C |
2x USB3.1 (DisplayPort optional) (Power Delivery optional) |
|
Kamera-Anschluss |
16x MIPI CSI-2 Lanes, bis zu 6 aktive Sensorströme |
|
M.2 Schlüssel M |
NVMe x4 |
|
M.2 Schlüssel E |
PCIe x1 (für Wi-Fi/ LTE/ 5G) + USB2 + UART + I2S/PCM |
|
40-polige Stiftleiste |
UART + SPI + CAN + I2C + I2S + DMIC + GPIOs |
|
HD-Audio-Header |
Hochauflösendes Audio |
|
eSATAp + USB 3.0 |
SATA über PCIe x1-Brücke (Strom + Daten für 2,5"-SATA) + USB 3.0 |
|
HDMI Typ A |
HDMI 2.0, Edp 1.2A, DP 1.4 |
|
Usd/ UFS-Kartensteckplatz |
SD/UFS |
Verfügbare E/A-Anschlüsse beim Jetson AGX Xavier Developer Kit
Intelligente Videoanalyse (IVA)
KI und Deep Learning ermöglichen die effektive Nutzung riesiger Datenmengen, um Städte sicherer und komfortabler zu machen, einschließlich Anwendungen wie Verkehrsmanagement, intelligentes Parken und optimierte Kassiervorgänge in Einzelhandelsgeschäften. NVIDIA Jetson und NVIDIA DeepStream SDK ermöglichen es verteilten Smart-Kameras, intelligente Videoanalysen in Echtzeit durchzuführen, die massive Bandbreitenbelastung der Übertragungsinfrastruktur zu reduzieren und die Sicherheit sowie die Anonymität zu verbessern.
Der Jetson TX2 kann zwei HD-Streams gleichzeitig verarbeiten und dabei Objekte erkennen und verfolgen. Wie im obigen Video zu sehen ist, kann der Jetson AGX Xavier 30 unabhängige HD-Videoströme gleichzeitig mit 1080p30 verarbeiten - eine 15-fache Verbesserung. Der Jetson AGX Xavier bietet einen Gesamtdurchsatz von über 1850MP/s und ist damit in der Lage, jedes Bild in etwas mehr als 1 Millisekunde zu dekodieren, vorzubearbeiten, Inferencing mit ResNet-basierter Erkennung durchzuführen und zu visualisieren. Die Fähigkeiten des Jetson AGX Xavier bringen ein deutlich höheres Maß an Leistung und Skalierbarkeit für die Edge-Videoanalyse.
Eine neue Ära der Autonomie
Jetson AGX Xavier bietet eine noch nie dagewesene Leistung an Bord von Robotern und intelligenten Maschinen. Diese Systeme benötigen anspruchsvolle Rechenleistung für KI-gesteuerte Wahrnehmung, Navigation und Manipulation, um einen robusten autonomen Betrieb zu ermöglichen. Zu den Anwendungsbereichen gehören die Fertigung, die industrielle Inspektion, die Präzisionslandwirtschaft und Dienstleistungen im Haushalt. Autonome Lieferroboter, die Pakete an Endverbraucher ausliefern und die Logistik in Lagerhäusern, Geschäften und Fabriken unterstützen, stellen eine Klasse von Anwendungen dar.
Eine typische Verarbeitungspipeline für vollautonome Zustellung und Logistik erfordert mehrere Stufen von Bildverarbeitungs- und Wahrnehmungsaufgaben, wie in der folgenden Abbildung dargestellt. Mobile Lieferroboter verfügen häufig über mehrere periphere HD-Kameras, die zusätzlich zu LIDAR und anderen Entfernungssensoren, die in der Software zusammen mit Trägheitssensoren fusioniert werden, ein 360°-Situationsbewusstsein bieten. Häufig wird eine nach vorne gerichtete Stereokamera verwendet, die eine Vorverarbeitung und Stereotiefenkartierung erfordert. NVIDIA hat hierfür Stereo-DNN-Modelle entwickelt, die eine höhere Genauigkeit als herkömmliche Block-Matching-Methoden bieten.
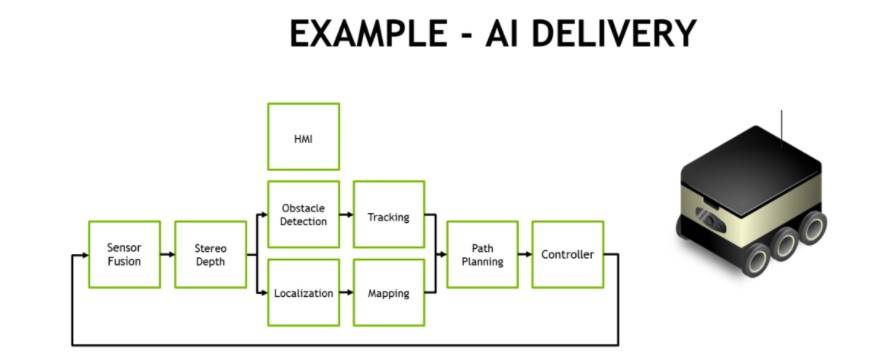 Beispiel für die KI-Verarbeitungspipeline eines autonomen Liefer- und Logistikroboters
Beispiel für die KI-Verarbeitungspipeline eines autonomen Liefer- und Logistikroboters
Objekterkennungsmodelle wie SSD oder Faster-RCNN und merkmalsbasierte Verfolgung dienen in der Regel der Hindernisvermeidung von Fußgängern, Fahrzeugen und Landmarken. Im Falle von Lager- und Ladenrobotern lokalisieren diese Objekterkennungsmodelle interessante Objekte wie Produkte, Regale und Strichcodes. Gesichtserkennung, Posenschätzung und automatische Spracherkennung (ASR) erleichtern die Mensch-Maschine-Interaktion (HMI), so dass der Roboter sich effektiv mit dem Menschen koordinieren und kommunizieren kann.
Simultane Lokalisierung und Kartierung (SLAM) mit hoher Framerate ist entscheidend, um die genaue Position des Roboters in 3D auf dem neuesten Stand zu halten. GPS allein ist für eine Positionierung im Submeterbereich zu ungenau und steht in Innenräumen nicht zur Verfügung. SLAM führt die Registrierung und den Abgleich der neuesten Sensordaten mit den früheren Daten durch, die das System in seiner Punktwolke gesammelt hat. Die häufig verrauschten Sensordaten müssen für eine korrekte Lokalisierung erheblich gefiltert werden, insbesondere bei sich bewegenden Plattformen.
In der Bahnplanungsphase werden häufig semantische Segmentierungsnetze wie ResNet-18 FCN, SegNet oder DeepLab zur Erkennung des freien Raums verwendet, um dem Roboter mitzuteilen, wo er ungehindert fahren kann. In der realen Welt gibt es häufig zu viele Arten von generischen Hindernissen, um sie einzeln zu erkennen und zu verfolgen, weshalb ein segmentierungsbasierter Ansatz jedes Pixel oder Voxel mit seiner Klassifizierung versieht. Zusammen mit den vorherigen Schritten der Pipeline informiert dies den Planer und den Regelkreis über die sicheren Routen, die er nehmen kann.
Die Leistung und Effizienz von Jetson AGX Xavier ermöglicht die Verarbeitung aller Komponenten in Echtzeit, die für einen sicheren und völlig autonomen Betrieb dieser Roboter erforderlich sind, einschließlich hochleistungsfähiger Bildverarbeitungsalgorithmen für die Wahrnehmung, Navigation und Manipulation in Echtzeit. Mit eigenständigen Jetson AGX Xavier-Modulen, die jetzt in Produktion gehen, können Entwickler diese KI-Lösungen für die nächste Generation autonomer Maschinen einsetzen.
Assured Systems und NVIDIA Jetson AGX Xavier
Unter Assured Systems bieten wir eine breite Palette von Jetson-Produkten an, darunter auch Jetson AGX Xavier-basierte Produkte, die Robotik- und Edge-Geräte mit bahnbrechenden Rechenleistungen ausstatten und High-End-Workstation-Performance auf eine Embedded-Plattform bringen, die hinsichtlich Größe, Gewicht und Leistung optimiert wurde.
Kontaktieren Sie uns jetzt für Ihre Projektanfragen.










